






Windows Server bleibt ein Eckpfeiler der IT-Infrastruktur für Tausende von Unternehmen. Unabhängig davon, ob Sie eine Legacy-Anwendung, eine moderne .NET-Umgebung oder eine kritische Datenbank betreiben – die Sicherstellung der Gesundheit Ihrer Windows-Server ist nicht optional. Es ist der Unterschied zwischen einer erholsamen Nacht und einer Notfall-Support-Sitzung um 2 Uhr morgens.
Im Jahr 2026 hat sich die Landschaft der Windows-Überwachung weiterentwickelt. Wir sind über einfache Verfügbarkeitsprüfungen hinausgegangen. Moderne Teams benötigen tiefere Einblicke in die Systemleistung, Sicherheitssignale und Anwendungsprotokolle. Die Windows-Überwachung fühlt sich jedoch oft wie eine Wahl zwischen zwei Extremen an. Auf der einen Seite stehen die integrierten Microsoft-Tools, die leistungsstark, aber fragmentiert sind. Auf der anderen Seite gibt es Enterprise-Observability-Plattformen, die unverhältnismäßig komplex und teuer sind.
Dieser Leitfaden soll diese Lücke schließen. Wir werden die grundlegenden Prinzipien der Windows-Überwachung, die spezifischen Metriken, die Sie verfolgen sollten, und die Tools untersuchen, die Ihnen helfen, dies effektiv und ohne den Enterprise-Overhead zu tun. Das Verständnis dafür, warum Serverüberwachung wichtig ist, ist der erste Schritt zum Aufbau einer zuverlässigen Infrastruktur.
Was ist Windows-Überwachung?
Windows-Überwachung ist der kontinuierliche Prozess des Sammelns und Analysierens von Daten Ihres Windows-Betriebssystems und der darauf laufenden Anwendungen. Sie umfasst die Überwachung der physikalischen und virtuellen Ressourcen des Servers, um sicherzustellen, dass sie innerhalb der erwarteten Parameter arbeiten.
Ein häufiger Fehler ist, Überwachung nur als Dashboard zu betrachten. In der Realität besteht eine effektive Windows-Überwachung aus drei Ebenen.
Infrastruktur-Metriken
Dies sind die numerischen Werte, die die „Vitalzeichen“ Ihrer Hardware oder VM darstellen. Denken Sie an CPU-Auslastung, Speicherdruck und Festplattenlatenz. Diese werden normalerweise über Performance Counter (PerfMon) gesammelt.
Ereignisprotokolle (Event Logs)
Windows zeichnet fast alles, was im System passiert, in Ereignisprotokollen auf. Dazu gehören Start-/Stopp-Ereignisse von Diensten, Anwendungsabstürze, Sicherheitsanmeldungen und Systemfehler. Wenn Metriken Ihnen sagen, wann ein Problem aufgetreten ist, sagen Ihnen Protokolle, warum es passiert ist.
Anwendungsgesundheit
Diese Ebene konzentriert sich auf die Software, die für Ihre Benutzer tatsächlich wichtig ist. Antwortet IIS auf Anfragen? Ist die Puffer-Cache-Trefferquote des SQL-Servers in Ordnung? Die Überwachung der Anwendungsebene stellt sicher, dass der Dienst tatsächlich funktioniert, selbst wenn der Server „aktiv“ ist.
Warum sich die Windows-Überwachung von der Linux-Überwachung unterscheidet
Wenn Sie aus einem Linux-Hintergrund kommen, kann sich die Windows-Überwachung ungewohnt anfühlen. In Linux ist „alles eine Datei“, und Sie sammeln Metriken oft durch das Lesen von Textdateien in /proc.
Windows verwendet einen strukturierteren Ansatz. Fast alle Leistungsdaten werden über das Performance Counter-System bereitgestellt. Der Zugriff auf diese Daten erforderte traditionell spezialisierte APIs oder WMI (Windows Management Instrumentation). Obwohl WMI leistungsstark ist, ist es auch bekanntlich ressourcenintensiv. Moderne Überwachungs-Tools im Jahr 2026 konzentrieren sich darauf, effizientere Methoden wie die Performance Counters API oder spezialisierte Exporter zu verwenden.
Performance Counter vs. WMI
Wenn Sie mit der Überwachung von Windows beginnen, werden Sie wahrscheinlich auf zwei Hauptwege stoßen, um Daten zu erhalten: Windows Management Instrumentation (WMI) und das Performance Counter-System. Den Unterschied zu verstehen, ist entscheidend, um die Leistung Ihres Servers aufrechtzuerhalten.
| Merkmal | Windows Management Instrumentation (WMI) | Performance Counter |
|---|---|---|
| Was es ist | Infrastruktur zur Verwaltung von OS-Daten und Operationen. | Mechanismus für hochfrequente Datenerfassung. |
| Sichtbarkeit | Fast alles (Seriennummern, CPU-Temperatur). | Numerische Werte, die in Echtzeit im Speicher aktualisiert werden. |
| Overhead | Bekannt für hohen CPU-Overhead; kann Leistungsprobleme verursachen. | Deutlich „günstiger“ und viel effizienter abzufragen. |
Die meisten modernen Überwachungsagenten bevorzugen die Performance Counter API für das Tracking von Metriken wie CPU- und Festplattennutzung und reservieren WMI nur für statische Informationen, die sich nicht oft ändern, wie die OS-Version oder der insgesamt installierte physische RAM.
# Liste der verfügbaren Prozessor-Performance-Counter abrufen
Get-Counter -ListSet Processor | Select-Object -ExpandProperty Counter
# Echtzeit-CPU-Auslastung alle 1 Sekunde abfragen
Get-Counter -Counter "\Processor(_Total)\% Processor Time" -SampleInterval 1 -MaxSamples 5Was man in Windows überwachen sollte
Die schiere Menge an Daten, die Windows exportieren kann, ist überwältigend. Wenn Sie versuchen, alles zu überwachen, werden Sie in einer Flut von Rauschen enden. Für die meisten Umgebungen sollten Sie sich auf die folgenden Kernbereiche konzentrieren.
CPU-Leistung und Engpässe
Die CPU-Auslastung ist die sichtbarste Metrik, aber sie ist oft ein nachlaufender Indikator. Sie müssen tiefer blicken als nur auf einen Prozentsatz.
| Metrik | Beschreibung | Kritischer Schwellenwert |
|---|---|---|
| % Prozessorzeit | Basis-Auslastung. | > 80 % konsistent |
| Prozessorwarteschlangenlänge | Threads, die auf die CPU warten. | > 2x Anzahl der Kerne |
| Kontextwechsel/Sek. | CPU-Overhead bei der Thread-Verwaltung. | Hohe/ungewöhnliche Spitzen |
Speicher- und Ressourcendruck
Windows nutzt RAM aggressiv für das Caching. Eine hohe Speicherauslastung ist nicht immer ein schlechtes Zeichen, aber Speicherdruck ist es.
| Metrik | Beschreibung | Risiko |
|---|---|---|
| Verfügbare MBytes | Verbleibender physischer Speicher für OS/Apps. | < 5-10 % des Gesamt-RAM |
| Seiten/Sek. | Harte Seitenfehler (Festplatten-Swapping). | Hohe Raten beeinträchtigen die Leistung massiv |
| Zugesicherte Bytes | Gesamter versprochener virtueller Speicher. | Nähert sich RAM + Auslagerungsdatei |
Festplatten-I/O und Latenz
Die Festplattenleistung ist die häufigste Ursache für „stille“ Verlangsamung. Ein Server kann eine CPU-Last von 0 % haben, sich aber völlig träge anfühlen, weil das Festplattensubsystem überlastet ist.
| Metrik | Beschreibung | Ziel |
|---|---|---|
| Durchschn. Sek./Lesen & Schreiben | Misst die Latenz in Sekunden. | < 10ms (Ausgezeichnet), > 50ms (Engpass) |
| % Zeit | Prozentsatz der Zeit, in der die Festplatte beschäftigt ist. | Hohe dauerhafte Nutzung ist riskant |
| Warteschlangenlänge | I/O-Anfragen, die auf die Festplatte warten. | Korrelieren mit hoher Latenz |
Netzwerkdurchsatz und Gesundheit
| Metrik | Beschreibung | Ziel |
|---|---|---|
| Gesamte Bytes/Sek. | Basis-Bandbreitennutzung. | Spitzen/Übertragungen identifizieren |
| Ausgabewarteschlangenlänge | Pakete, die auf den Versand warten. | Sollte 0 sein |
| Empfangene Paketfehler | Beschädigte oder fehlgeschlagene Pakete. | Sollte 0 sein |
Überwachung von Windows-Diensten und -Prozessen
Über die Kernhardware-Metriken hinaus müssen Sie sicherstellen, dass Ihre kritischen Hintergrundprozesse tatsächlich laufen. Windows verwendet „Dienste“, um alles zu verwalten, von Ihrem Webserver (IIS) bis zu Ihrer Datenbank (SQL Server).
# Status eines spezifischen Dienstes prüfen (z. B. World Wide Web Publishing Service)
Get-Service -Name W3SVC
# Liste aller Dienste, die auf automatischen Start gesetzt, aber derzeit gestoppt sind
Get-Service | Where-Object { $_.StartType -eq 'Automatic' -and $_.Status -eq 'Stopped' }- Dienstgesundheit: Sie sollten den Status jedes Dienstes überwachen, der für das Funktionieren Ihrer Anwendung erforderlich ist. Ein Dienst, der auf „Automatisch“ gestellt ist, aber derzeit „Gestoppt“ ist, ist ein klares Zeichen für ein Problem, wahrscheinlich ein Absturz oder eine fehlgeschlagene Abhängigkeit.
- Prozess-Arbeitssatz (Working Set): Dies misst die Menge an physischem Speicher, die derzeit von einem bestimmten Prozess verwendet wird. Wenn der Arbeitssatz einer bestimmten Anwendung ständig wächst, ohne jemals zu sinken, haben Sie ein Speicherleck.
- Handle-Anzahl pro Prozess: Ein „Handle“ ist ein Verweis auf eine Systemressource (wie eine Datei oder einen Registrierungsschlüssel). Wenn die Handle-Anzahl eines Prozesses kontinuierlich steigt, werden Ressourcen nicht freigegeben, was schließlich zu systemweiten Instabilitäten führt.
- Benutzereingabeverzögerung: In Remote-Desktop-Umgebungen (RDS) ist die Überwachung der Verzögerung zwischen einer Benutzereingabe und der Antwort der Anwendung entscheidend, um die tatsächliche Benutzererfahrung zu verstehen, die Hardwaremetriken möglicherweise übersehen.
Windows-Ereignisprotokolle
Metriken geben Ihnen das „Was“, aber Ereignisprotokolle geben Ihnen das „Wer“ und „Wie“. Sie sollten sich auf diese vier Hauptprotokolle konzentrieren:
- Systemprotokoll: Kritisch für Hardwareprobleme, Treiberfehler und Fehler auf OS-Ebene.
- Anwendungsprotokoll: Hier zeichnet Ihre Software (und Drittanbieter-Apps) ihre Fehler und Warnungen auf.
- Sicherheitsprotokoll: Essentiell für Audits. Sie sollten auf fehlgeschlagene Anmeldungen, Kontosperrungen und Änderungen an Administratorgruppen achten.
- Installationsprotokoll: Nützlich bei Updates und Neuinstallationen von Software.
# Die 10 neuesten Fehlerereignisse aus dem Systemprotokoll abrufen
Get-WinEvent -LogName System -MaxEvents 10 | Where-Object { $_.LevelDisplayName -eq "Error" }
# Alle 'Kritischen' Ereignisse der letzten 24 Stunden auflisten
Get-WinEvent -FilterHashtable @{LogName='System'; Level=1; StartTime=(Get-Date).AddDays(-1)}Im Jahr 2026 sollten Sie diese Protokolle nicht mehr manuell in der Ereignisanzeige durchsuchen. Sie benötigen eine Möglichkeit, Ereignisse auf der Ebene „Fehler“ oder „Kritisch“ zu zentralisieren und zu alarmieren.
Gängige Ansätze und Tools
Die Wahl eines Überwachungs-Tools für Windows hängt von der Größe Ihrer Umgebung und dem Grad der Komplexität ab, den Sie bereit sind zu verwalten. Hier sind die gängigsten Ansätze, die Teams heute verwenden.
Native Microsoft-Tools (Sysinternals und PerfMon)
Microsoft bietet leistungsstarke Tools direkt ab Werk an. Der Performance Monitor (PerfMon) ist der Standard für die Echtzeit- und historische Metrikanalalyse auf einer einzelnen Maschine. Für die tiefe Fehlersuche ist die Sysinternals-Suite (einschließlich Process Monitor und Process Explorer) unverzichtbar.
- Für wen es ist: Ad-hoc-Fehlersuche und Tiefenanalyse spezifischer Leistungsprobleme.
- Vorteile: Kostenlos, integriert (oder einfach herunterladbar) und extrem detailliert.
- Nachteile: Keine zentralisierte Alarmierung oder historische Speicherung über mehrere Server hinweg. Es ist ein manueller Ansatz für jeweils einen Server.
Open-Source-Stacks (Prometheus und Grafana)
Der beliebteste Open-Source-Ansatz im Jahr 2026 ist die Verwendung des windows_exporter, um Metriken zu sammeln und an einen Prometheus-Server zu senden, mit Grafana zur Visualisierung.
- Für wen es ist: Teams, die ihre eigene Linux-basierte Überwachungsinfrastruktur verwalten möchten, um ihre Windows-Flotte zu überwachen.
- Vorteile: Hochgradig anpassbar, riesiges Ökosystem und keine Lizenzkosten für die Software.
- Nachteile: Erhebliche operative Belastung. Sie müssen die Exporter, den Prometheus-Server und die Grafana-Dashboards verwalten. Das Einrichten Windows-spezifischer Alarme erfordert tiefe Kenntnisse der Metriken des Exporters.
Simple Observability
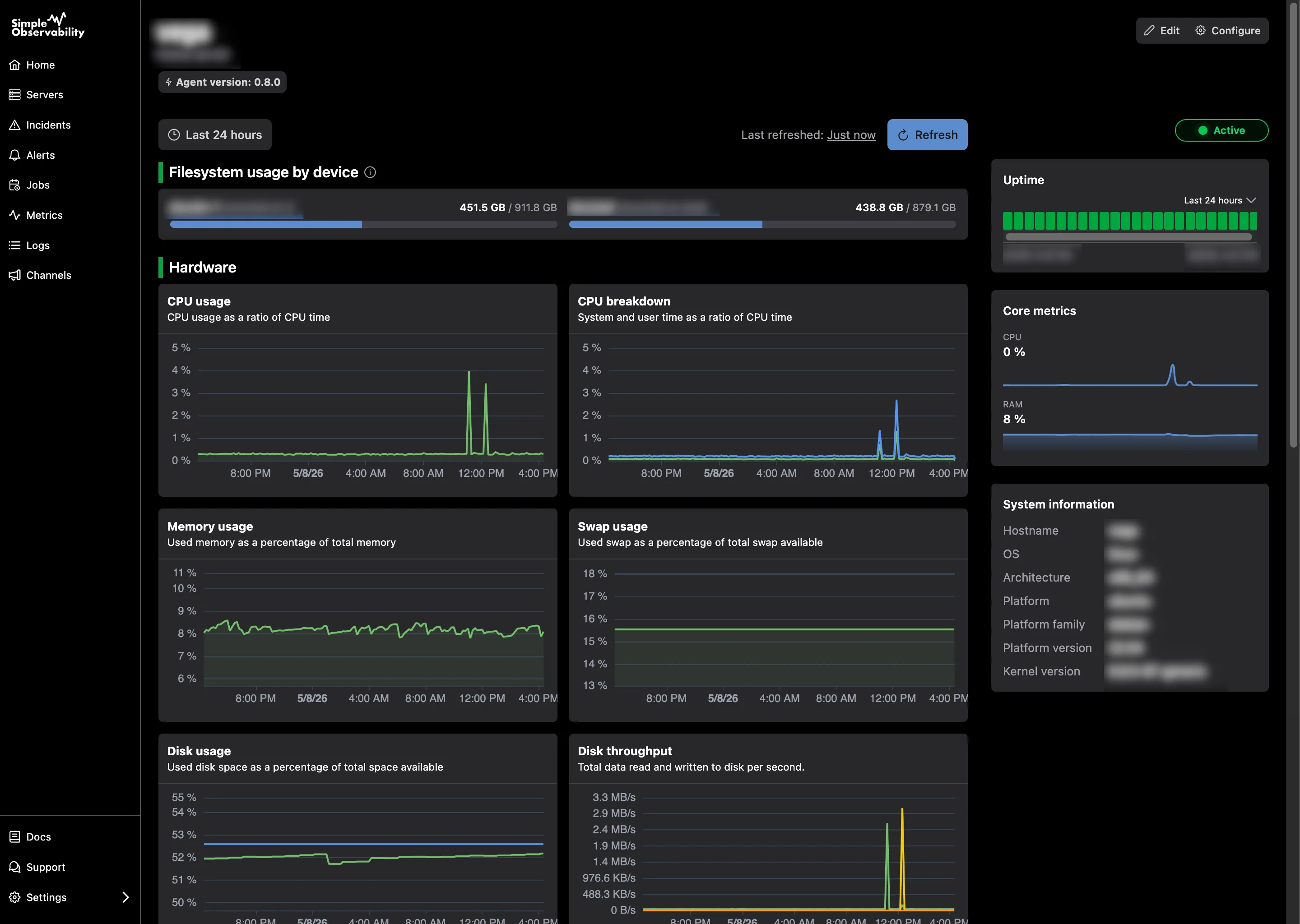
Simple Observability bietet einen leichtgewichtigen, einheitlichen Ansatz zur Überwachung von Metriken, Protokollen und Alarmen auf Windows-Servern ohne die Komplexität traditioneller Stacks. Er ist als „Set and Forget“-Lösung für Teams konzipiert, die unsere Windows-Produktseite informativ finden, aber zuerst einen tieferen Leitfaden suchen. Viele Teams, die nach Netdata-Alternativen für Windows suchen, finden diesen einheitlichen Ansatz besonders wertvoll.
- Für wen es ist: Systemadministratoren und Entwickler, die eine produktionsreife Transparenz über mehrere Server mit einem Ein-Befehl-Setup wünschen.
- Vorteile: Kombiniert Metriken und Ereignisprotokolle in einer Benutzeroberfläche, automatische Einrichtung kritischer Windows-Alarme und sehr geringer Ressourcenverbrauch.
- Nachteile: Nicht gedacht für Unternehmen mit Tausenden von Servern und ultra-spezialisierten Nischenanforderungen.
Enterprise-Plattformen (Zabbix, SolarWinds, Dynatrace)
Dies sind die „großen Player“ der Überwachungswelt. Sie bieten alles von der Bestandsverwaltung bis zur KI-gesteuerten Anomalieerkennung. Viele Teams suchen jedoch nach Zabbix-Alternativen aufgrund der schieren Komplexität und der Kosten dieser Plattformen.
- Für wen es ist: Große Unternehmen mit massiven, heterogenen Umgebungen.
- Vorteile: Umfassende Funktionen und professioneller Support.
- Nachteile: Teure Lizenzierung, steile Lernkurve und erfordert oft ein dediziertes Team nur zur Verwaltung des Überwachungs-Tools selbst.
Vergleich von Windows-Überwachungs-Tools
| Tool | Typ | Komplexität | Beste für… |
|---|---|---|---|
| PerfMon | Natives Tool | Niedrig | Schnelles lokales Debugging |
| Prometheus | Open Source | Hoch | Eigene DIY-Flotten |
| Simple Observability | SaaS/Einheitlich | Niedrig | Kleine bis mittlere Teams |
| Zabbix | Enterprise | Hoch | Große Umgebungen |
| Datadog | SaaS/APM | Mittel | Full-Stack-Observability |
Best Practices für die Windows-Überwachung
Das Einrichten eines Tools ist erst der erste Schritt. Um sicherzustellen, dass Ihre Überwachung tatsächlich nützlich ist, sollten Sie diese Industriestandards befolgen.
Einer der größten Fehler, den Teams machen, ist das Einrichten von zu vielen Alarmen. Wenn Sie jedes Mal eine E-Mail erhalten, wenn die CPU für ein paar Sekunden auf 90 % ansteigt, werden Sie Ihren Posteingang bald ignorieren. Dies ist die „Alarm-Müdigkeit“.
Konzentrieren Sie sich stattdessen auf anhaltende Probleme. Stellen Sie Ihre Alarme so ein, dass sie nur ausgelöst werden, wenn eine Metrik für eine bestimmte Dauer (z. B. 5–10 Minuten) über einem Schwellenwert bleibt. Stellen Sie speziell für Windows sicher, dass Sie bei „Kritisch“- und „Fehler“-Ereignissen in den System- und Anwendungsprotokollen alarmieren, aber das „Informations“-Rauschen herausfiltern.
Erstellen Sie eine Leistungsbasis (Baseline)
Sie können nicht wissen, ob Ihr Server schlecht abschneidet, wenn Sie nicht wissen, wie „normal“ aussieht. Verbringen Sie nach dem Einrichten Ihrer Überwachung eine Woche damit, die Metriken zu beobachten. Wie hoch ist die typische CPU-Last während der Geschäftszeiten? Wie viel RAM ist normalerweise frei? Verwenden Sie diese Daten, um realistische Alarmschwellenwerte festzulegen, anstatt sich auf generische Standardwerte zu verlassen.
Verwenden Sie leichtgewichtige Agenten
Windows-Server sind oft ressourcenbeschränkt. Vermeiden Sie Überwachungs-Tools, die schwere Java-basierte Agenten verwenden oder sich stark auf WMI verlassen. Suchen Sie nach Agenten, die in performanten Sprachen wie Go oder Rust geschrieben sind und minimale Auswirkungen auf die CPU und den Speicher des Host-Systems haben. Wir glauben, dass Leichtgewichtigkeit eine Metrik ist, nicht nur ein Adjektiv, und wir priorisieren Effizienz in jeder Komponente.
Kombinieren Sie Metriken und Protokolle
Überwachen Sie Metriken niemals isoliert. Ein CPU-Spike sagt sehr wenig aus, wenn Sie ihn nicht mit einem Fehler im Ereignisprotokoll korrelieren können. Ein einheitlicher Ansatz, bei dem Sie Ihre Graphen und Ihre Protokolle auf derselben Zeitachse sehen können, wird Ihre „Mean Time to Resolution“ (MTTR) erheblich reduzieren.
Überwachen Sie von außen nach innen (Outside-In)
Interne Metriken sagen Ihnen, ob der Server gesund ist, aber sie sagen Ihnen nicht, ob Ihre Benutzer Ihre Anwendung tatsächlich erreichen können. Kombinieren Sie Ihre interne Windows-Überwachung immer mit externen Verfügbarkeitsprüfungen. Dies stellt sicher, dass Sie alarmiert werden, wenn eine Firewall-Änderung oder ein DNS-Problem die Konnektivität unterbricht, selbst wenn der Server „grün“ ist.
Fazit
Die Windows-Überwachung im Jahr 2026 muss keine Wahl zwischen „komplex“ und „unvollständig“ sein. Indem Sie sich auf die Kernsignale konzentrieren – insbesondere CPU-Warteschlangen, Speicherdruck, Festplattenlatenz und kritische Ereignisprotokolle –, können Sie eine robuste Überwachungsstrategie aufbauen, die mit Ihren Anforderungen wächst.
Ob Sie sich für einen benutzerdefinierten Stack mit Prometheus entscheiden, die integrierten Microsoft-Tools für das lokale Debugging verwenden oder sich für eine einheitliche Plattform wie Simple Observability entscheiden – der Schlüssel ist der Übergang von reaktiver Fehlersuche zu proaktivem Management.
Für Teams, die eine sofort einsatzbereite Windows-Überwachungslösung suchen, bietet Simple Observability ein Ein-Befehl-Setup und einheitliche Metriken + Protokolle. So können Sie weniger Zeit mit der Verwaltung Ihrer Überwachung und mehr Zeit mit der Verwaltung Ihrer Infrastruktur verbringen.