How to monitor your home lab with one command?
You could spend your weekend calculating storage retention for Prometheus and writing alerting rules in YAML, or you could simply run one command.
Why not just self-host?
"Free" tools still cost you servers, storage, and days debugging YAML configs.
The "Free" Stack
Setting up tools like Checkmk, Zabbix, or Netdata often seems simple at first, but the hidden costs of maintenance, configuration, and infrastructure quickly add up.
- Provision and secure servers (networking, firewall, TLS)
- Configure persistent storage and backups
- Monitor the monitoring system itself
- Handle updates, patches, and compatibility issues
- …
Simple Observability
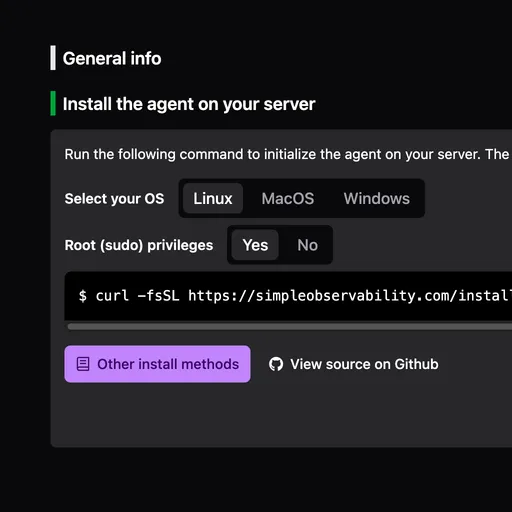
curl -fsSL https://simpleobservability.com/install.sh | sudo bash -s -- <SERVER KEY>One command installs an agent that ships metrics and logs to a hosted platform. Dashboards and alerts are already configured.
Set up your homelab monitoring in under 2 minutes
Run the install command on your local servers, connect them in the web UI, and start tracking health and resource usage.
Install the agent
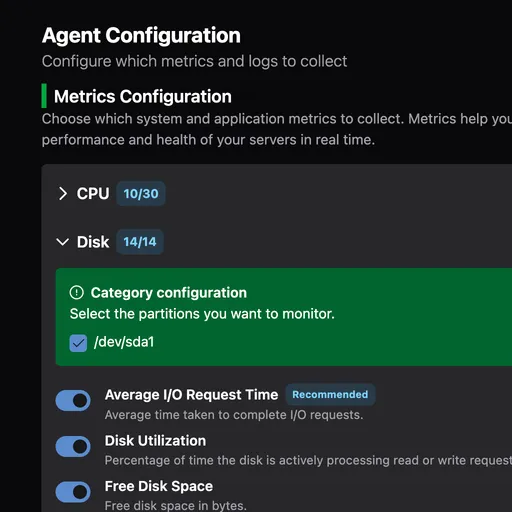
Configure from the UI
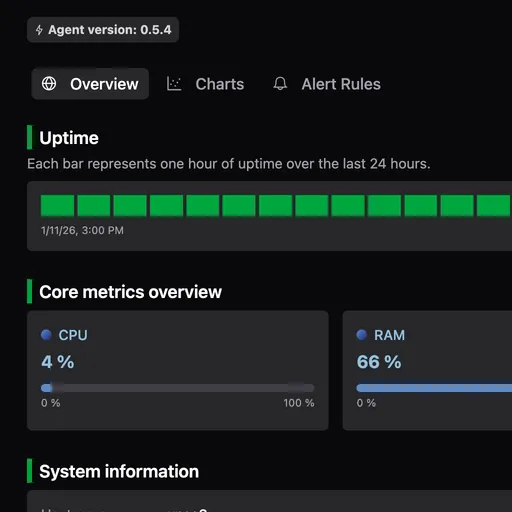
Get instant insights
Everything you need for your home lab
Monitor CPU and memory usage, search through system logs, and track the execution and output logs of your scheduled background tasks.

Metrics
Track CPU, RAM, disk, and network with minimal overhead.

Logs
Centralize and search logs without setting up pipelines.

Cron Monitoring
Track execution, duration, and exit codes. Capture output logs from your running jobs and get alerted on failures.

Alerts
Set threshold-based alerts. Integrates with Slack, Discord, and other channels.
Why Simple Observability is the best monitoring solution for your servers?
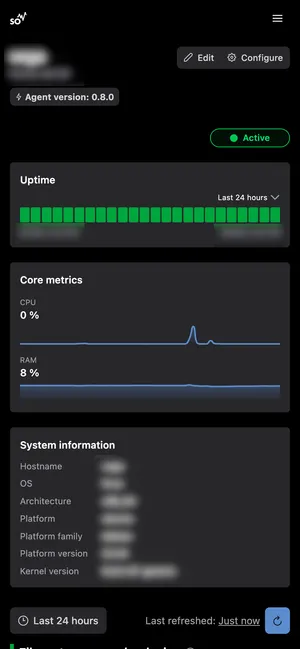
A look inside Simple Observability UI
Instantly see how Simple Observability helps you monitor and troubleshoot, all from a single UI.




Keep an eye on your servers from anywhere
Lightweight is a metric,
not an adjective.
“Lightweight” isn’t a promise, it’s something we measure.
simob is built to have a minimal footprint, with close attention to memory usage and CPU consumption,
so monitoring stays out of the way of your workloads.
Complete observability, simplified
Simple Observability delivers all essential monitoring capabilities in one streamlined package. We've eliminated the complexity while keeping the powerful features you need to maintain reliable systems.
Stop cobbling together multiple tools and managing complicated stacks.
Zero Inbound Ports.
Most monitoring agents require you to poke holes in your firewall or manage complex access lists.
We don't. simob strictly pushes data outbound.
Your firewall stays completely closed.
Works with your entire stack
Simple Observability comes with dozens of built-in integrations for your favourite tools. Zero configuration required, just toggle and go.







Stop worrying about your monitoring stack.
Get back to building your homelab. We'll handle the observability.