






O Windows Server continua sendo um pilar central da infraestrutura de TI para milhares de empresas. Quer você esteja executando uma aplicação legada, um ambiente .NET moderno ou um banco de dados crítico, garantir a saúde de seus servidores Windows não é opcional. É a diferença entre uma noite tranquila e uma sessão de resolução de problemas às 2 da manhã.
Em 2026, o cenário do monitoramento Windows evoluiu. Fomos além das simples verificações de disponibilidade. As equipes modernas precisam de visibilidade mais profunda do desempenho do sistema, sinais de segurança e logs de aplicações. No entanto, o monitoramento Windows muitas vezes parece uma escolha entre dois extremos. De um lado, as ferramentas nativas da Microsoft, que são poderosas, mas fragmentadas. Do outro, as plataformas de observabilidade empresarial, proibitivamente complexas e caras.
Este guia visa preencher essa lacuna. Exploraremos os princípios fundamentais do monitoramento Windows, as métricas específicas que você deve acompanhar e as ferramentas que ajudam a fazê-lo de forma eficaz sem a sobrecarga empresarial.
O que é monitoramento Windows?
O monitoramento Windows é o processo contínuo de coletar e analisar dados do seu sistema operacional Windows e das aplicações que rodam sobre ele. Envolve observar os recursos físicos e virtuais do servidor para garantir que estejam operando dentro dos parâmetros esperados.
Um erro comum é pensar no monitoramento como apenas um painel. Na realidade, o monitoramento eficaz do Windows consiste em três camadas.
Métricas de infraestrutura
São os valores numéricos que representam os “sinais vitais” do seu hardware ou VM. Pense em utilização de CPU, pressão de memória e latência de disco. Geralmente são coletados via Contadores de Desempenho (PerfMon).
Logs de eventos
O Windows registra quase tudo o que acontece no sistema dentro dos Logs de Eventos. Isso inclui eventos de início/parada de serviços, falhas de aplicações, logins de segurança e erros do sistema. Se as métricas informam quando um problema ocorreu, os logs informam por que ele aconteceu.
Integridade da aplicação
Esta camada foca no software que seus usuários realmente utilizam. O IIS está respondendo às requisições? A taxa de acerto do cache de buffer do SQL Server está saudável? Monitorar a camada de aplicação garante que, mesmo que o servidor esteja “no ar”, o serviço esteja realmente funcionando.
Por que o Windows é diferente do monitoramento Linux
Se você vem de um ambiente Linux, o monitoramento Windows pode parecer estranho. No Linux, “tudo é um arquivo”, e você frequentemente coleta métricas lendo arquivos de texto em /proc.
O Windows usa uma abordagem mais estruturada. Praticamente todos os dados de desempenho são expostos através do sistema de Contadores de Desempenho. Acessar esses dados tradicionalmente exigia APIs especializadas ou WMI (Windows Management Instrumentation). Embora o WMI seja poderoso, ele é notoriamente pesado em recursos. As ferramentas de monitoramento modernas em 2026 focam em métodos mais eficientes, como a API de Contadores de Desempenho ou exportadores especializados.
Contadores de desempenho vs. WMI
| Recurso | WMI | Contadores de Desempenho |
|---|---|---|
| O que é | Infraestrutura para gerenciar dados e operações do SO. | Mecanismo para coleta de dados de alta frequência. |
| Visibilidade | Quase tudo (números de série, temperatura da CPU). | Valores numéricos atualizados na memória em tempo real. |
| Overhead | Alto overhead de CPU; pode causar problemas de desempenho. | Significativamente mais eficiente de consultar. |
A maioria dos agentes modernos prefere a API de Contadores de Desempenho para métricas como CPU e disco, reservando o WMI apenas para informações estáticas como versão do SO ou RAM total instalada.
# Listar contadores de desempenho do processador disponíveis
Get-Counter -ListSet Processor | Select-Object -ExpandProperty Counter
# Consultar utilização de CPU em tempo real a cada 1 segundo
Get-Counter -Counter "\Processor(_Total)\% Processor Time" -SampleInterval 1 -MaxSamples 5O que monitorar no Windows
Desempenho de CPU e gargalos
| Métrica | Descrição | Limite crítico |
|---|---|---|
| % Tempo do processador | Utilização básica. | > 80% de forma sustentada |
| Comprimento da fila do processador | Threads aguardando CPU. | > 2x o número de núcleos |
| Trocas de contexto/seg | Overhead da CPU gerenciando threads. | Picos altos/incomuns |
Memória e pressão de recursos
| Métrica | Descrição | Risco |
|---|---|---|
| MBytes disponíveis | Memória física restante para SO/Apps. | < 5-10% da RAM total |
| Páginas/seg | Falhas de página forçadas (swap em disco). | Taxas altas destroem o desempenho |
| Bytes confirmados | Total de memória virtual comprometida. | Aproximando-se da RAM + arquivo de paginação |
E/S de disco e latência
O desempenho do disco é a causa mais comum de lentidão “silenciosa”. Um servidor pode ter 0% de carga de CPU, mas parecer completamente irresponsivo porque o subsistema de disco está sobrecarregado.
| Métrica | Descrição | Meta |
|---|---|---|
| Média de seg/Leitura e Escrita | Latência em segundos. | < 10ms (Excelente), > 50ms (Gargalo) |
| % Tempo de disco | Percentual do tempo que o disco está ocupado. | Uso sustentado alto é arriscado |
| Comprimento da fila do disco | Requisições de E/S aguardando o disco. | Correlacionar com alta latência |
Throughput e integridade da rede
| Métrica | Descrição | Meta |
|---|---|---|
| Total de bytes/seg | Uso básico de largura de banda. | Identificar picos/transferências |
| Comprimento da fila de saída | Pacotes aguardando envio. | Deve ser 0 |
| Erros de pacotes recebidos | Pacotes corrompidos ou com falha. | Deve ser 0 |
Monitoramento de serviços e processos
# Verificar o status de um serviço específico (ex: IIS)
Get-Service -Name W3SVC
# Listar serviços configurados para iniciar automaticamente, mas atualmente parados
Get-Service | Where-Object { $_.StartType -eq 'Automatic' -and $_.Status -eq 'Stopped' }- Integridade do serviço: Um serviço configurado como “Automático” mas “Parado” é um sinal claro de problema.
- Working set do processo: Se o working set de uma aplicação cresce sem nunca diminuir, há um vazamento de memória.
- Contagem de handles por processo: Se aumenta continuamente, o processo está falhando em liberar recursos do sistema.
- Atraso de entrada do usuário: Em ambientes RDS, fundamental para entender a experiência real do usuário.
Logs de eventos do Windows
- Log do Sistema: Crítico para problemas de hardware, falhas de driver e erros de SO.
- Log de Aplicativo: Onde software e aplicativos de terceiros registram erros e avisos.
- Log de Segurança: Monitore logins com falha, bloqueios de conta e alterações em grupos administrativos.
- Log de Instalação: Útil durante atualizações e novas instalações de software.
# Obter os 10 eventos de erro mais recentes do log do Sistema
Get-WinEvent -LogName System -MaxEvents 10 | Where-Object { $_.LevelDisplayName -eq "Error" }
# Listar todos os eventos 'Críticos' nas últimas 24 horas
Get-WinEvent -FilterHashtable @{LogName='System'; Level=1; StartTime=(Get-Date).AddDays(-1)}Em 2026, você não deveria estar rolando manualmente por esses logs no Visualizador de Eventos. Você precisa centralizar e alertar sobre eventos “Erro” ou “Crítico”.
Abordagens e ferramentas comuns
Ferramentas nativas da Microsoft (Sysinternals e PerfMon)
- Para quem é: Solução de problemas ad-hoc e análise aprofundada de desempenho.
- Prós: Gratuito, integrado e extremamente detalhado.
- Contras: Sem alertas centralizados ou armazenamento histórico em múltiplos servidores.
Stacks open source (Prometheus e Grafana)
O windows_exporter coleta métricas e as envia a um servidor Prometheus, com Grafana para visualização.
- Para quem é: Equipes confortáveis em gerenciar infraestrutura de monitoramento baseada em Linux.
- Prós: Altamente personalizável, enorme ecossistema e sem custos de licenciamento.
- Contras: Carga operacional significativa. Você gerencia exportadores, Prometheus e dashboards do Grafana.
Simple Observability
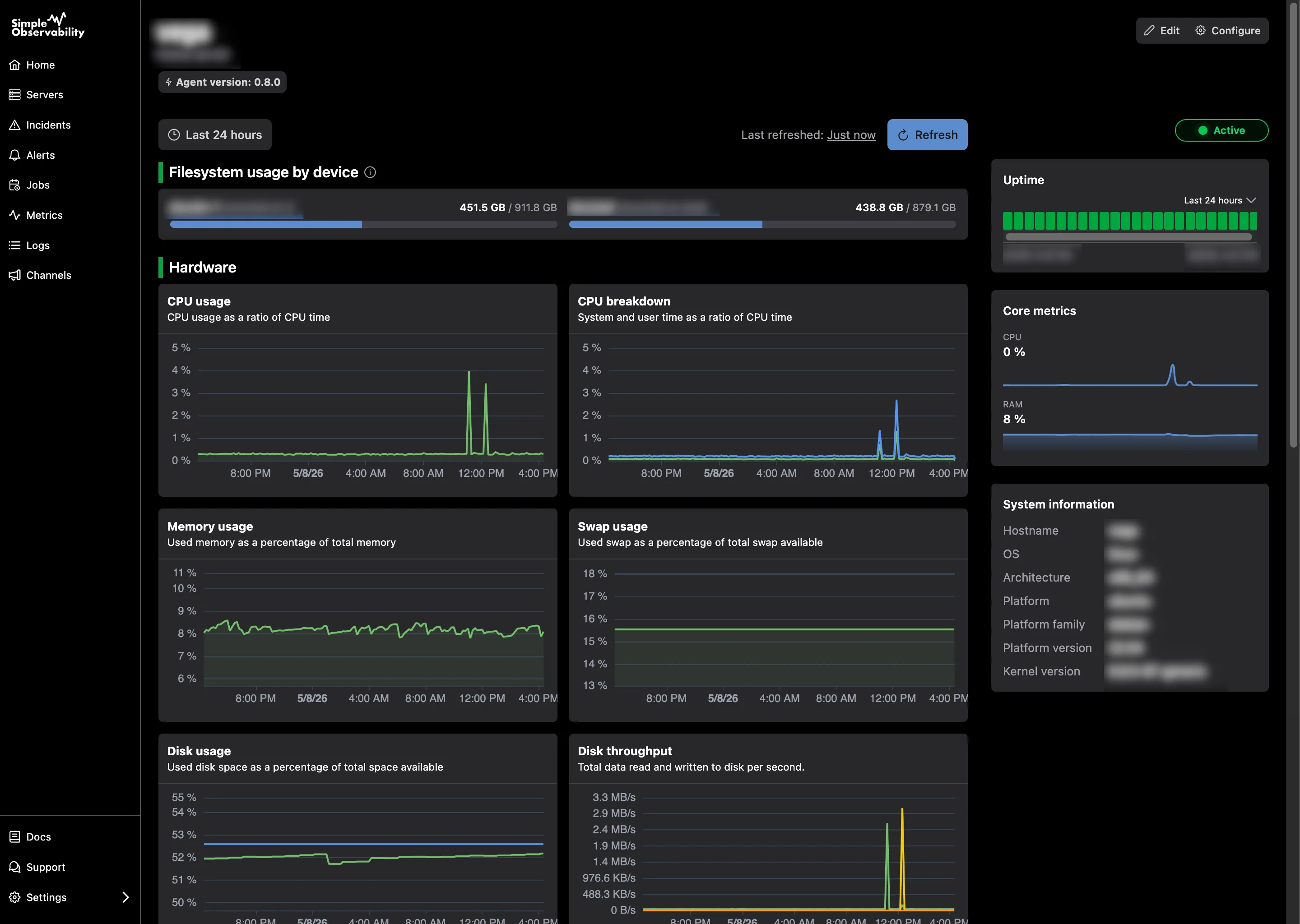
O Simple Observability oferece uma abordagem leve e unificada para monitorar métricas, logs e alertas em servidores Windows sem a complexidade dos stacks tradicionais.
- Para quem é: Sysadmins e desenvolvedores que desejam visibilidade de nível de produção em múltiplos servidores com configuração de um único comando.
- Prós: Combina métricas e logs de eventos em uma interface unificada, alertas críticos automáticos e footprint de recursos muito baixo.
- Contras: Não destinado a empresas com milhares de servidores e requisitos ultra especializados.
Plataformas empresariais (Zabbix, SolarWinds, Dynatrace)
- Para quem é: Grandes empresas com ambientes massivos e heterogêneos.
- Prós: Recursos abrangentes e suporte profissional.
- Contras: Licenciamento caro, curva de aprendizado acentuada e equipe dedicada para gerenciar a ferramenta.
Comparação de ferramentas
| Ferramenta | Tipo | Complexidade | Melhor para… |
|---|---|---|---|
| PerfMon | Ferramenta Nativa | Baixa | Debug local rápido |
| Prometheus | Open Source | Alta | Frotas personalizadas/DIY |
| Simple Observability | SaaS/Unificado | Baixa | Equipes pequenas-médias |
| Zabbix | Empresarial | Alta | Ambientes de grande escala |
| Datadog | SaaS/APM | Média | Observabilidade full-stack |
Melhores práticas para monitoramento Windows
Um dos maiores erros é configurar alertas em excesso. Se você receber um e-mail toda vez que a CPU disparar para 90% por alguns segundos, logo começará a ignorar sua caixa de entrada. Isso é “fadiga de alertas”.
Em vez disso, foque em problemas sustentados. Configure alertas para disparar somente quando uma métrica permanecer acima de um limite por uma duração específica (ex: 5-10 minutos). Para Windows, alerte sobre eventos “Críticos” e “Erro” nos logs do Sistema e Aplicativo, filtrando o ruído de “Informação”.
Estabeleça uma linha de base de desempenho
Após configurar o monitoramento, passe uma semana observando as métricas. Qual é a carga típica de CPU durante o horário de trabalho? Quanta RAM está livre? Use esses dados para definir limites de alerta realistas.
Use agentes leves
Evite ferramentas com agentes pesados baseados em Java ou que dependam fortemente de WMI. Procure agentes em linguagens eficientes como Go ou Rust. Acreditamos que ser leve é uma métrica, não apenas um adjetivo.
Combine métricas e logs
Um pico no uso de CPU tem pouco significado sem correlação com um erro no Log de Eventos. Uma abordagem unificada reduzirá significativamente seu “Tempo Médio de Resolução” (MTTR).
Monitore de fora para dentro
Combine seu monitoramento interno do Windows com verificações de disponibilidade externas. Isso garante que você seja alertado sobre problemas de firewall ou DNS mesmo quando o servidor está “verde”.
Conclusão
O monitoramento Windows em 2026 não precisa ser uma escolha entre “complexo” e “incompleto”. Focando nos sinais principais — filas de CPU, pressão de memória, latência de disco e logs de eventos críticos — você pode construir uma estratégia robusta que escala com suas necessidades.
Para equipes que buscam uma solução pronta para usar, o Simple Observability oferece configuração de um único comando e métricas + logs unificados. Gaste menos tempo gerenciando seu monitoramento e mais tempo gerenciando sua infraestrutura.