






Windows Server sigue siendo un pilar fundamental de la infraestructura TI para miles de empresas. Ya sea que estés ejecutando una aplicación heredada, un entorno .NET moderno o una base de datos crítica, garantizar la salud de tus servidores Windows no es opcional. Es la diferencia entre una noche tranquila y una sesión de resolución de problemas a las 2 de la madrugada.
En 2026, el panorama de la monitorización de Windows ha evolucionado. Hemos ido más allá de las simples comprobaciones de disponibilidad. Los equipos modernos requieren una visibilidad más profunda del rendimiento del sistema, las señales de seguridad y los registros de aplicaciones. Sin embargo, la monitorización de Windows a menudo parece una elección entre dos extremos. Por un lado, tienes las herramientas nativas de Microsoft, que son potentes pero fragmentadas. Por el otro, las plataformas de observabilidad empresarial, que son prohibitivamente complejas y costosas.
Esta guía pretende llenar ese vacío. Exploraremos los principios fundamentales de la monitorización de Windows, las métricas específicas que debes seguir y las herramientas que te ayudan a hacerlo de forma eficaz sin la sobrecarga empresarial. Comprender por qué es importante la monitorización de servidores es el primer paso para construir una infraestructura fiable.
¿Qué es la monitorización de Windows?
La monitorización de Windows es el proceso continuo de recopilar y analizar datos de tu sistema operativo Windows y las aplicaciones que se ejecutan sobre él. Implica observar los recursos físicos y virtuales del servidor para garantizar que funcionan dentro de los parámetros esperados.
Un error común es pensar en la monitorización como un simple panel de control. En realidad, la monitorización efectiva de Windows consta de tres capas.
Métricas de infraestructura
Son los valores numéricos que representan los «signos vitales» de tu hardware o VM. Piensa en la utilización de la CPU, la presión de la memoria y la latencia del disco. Normalmente se recopilan a través de los Contadores de Rendimiento (PerfMon).
Registros de eventos
Windows registra casi todo lo que ocurre en el sistema en los Registros de Eventos. Esto incluye eventos de inicio/detención de servicios, fallos de aplicaciones, inicios de sesión de seguridad y errores del sistema. Si las métricas te indican cuándo ocurrió un problema, los registros te indican por qué ocurrió.
Estado de la aplicación
Esta capa se centra en el software que realmente les importa a tus usuarios. ¿Está IIS respondiendo a las solicitudes? ¿Es saludable la tasa de aciertos de caché del buffer de SQL Server? La monitorización de la capa de aplicación garantiza que, aunque el servidor esté «activo», el servicio funcione realmente.
Por qué Windows es diferente de la monitorización de Linux
Si vienes de un entorno Linux, la monitorización de Windows puede resultarte desconocida. En Linux, «todo es un archivo», y a menudo recopilas métricas leyendo archivos de texto en /proc.
Windows utiliza un enfoque más estructurado. Casi todos los datos de rendimiento se exponen a través del sistema de Contadores de Rendimiento. El acceso a estos datos requería tradicionalmente API especializadas o WMI (Instrumental de Administración de Windows). Aunque WMI es potente, también es notoriamente intensivo en recursos. Las herramientas de monitorización modernas en 2026 se centran en utilizar métodos más eficientes como la API de Contadores de Rendimiento o exportadores especializados.
Contadores de rendimiento vs. WMI
Cuando empieces a monitorizar Windows, probablemente te encuentres con dos formas principales de obtener datos: Instrumental de Administración de Windows (WMI) y el sistema de Contadores de Rendimiento. Comprender la diferencia es clave para mantener tu servidor con buen rendimiento.
| Característica | Instrumental de Administración de Windows (WMI) | Contadores de Rendimiento |
|---|---|---|
| Qué es | Infraestructura para gestionar datos y operaciones del SO. | Mecanismo para la recopilación de datos de alta frecuencia. |
| Visibilidad | Casi todo (números de serie, temperatura de CPU). | Valores numéricos actualizados en memoria en tiempo real. |
| Sobrecarga | Conocido por alta sobrecarga de CPU; puede causar problemas de rendimiento. | Significativamente «más barato» y mucho más eficiente de consultar. |
La mayoría de los agentes de monitorización modernos prefieren la API de Contadores de Rendimiento para rastrear métricas como el uso de CPU y disco, reservando WMI solo para información estática que no cambia con frecuencia, como la versión del SO o la RAM física total instalada.
# Obtener una lista de contadores de rendimiento del procesador disponibles
Get-Counter -ListSet Processor | Select-Object -ExpandProperty Counter
# Consultar la utilización de CPU en tiempo real cada 1 segundo
Get-Counter -Counter "\Processor(_Total)\% Processor Time" -SampleInterval 1 -MaxSamples 5Qué monitorizar en Windows
El volumen de datos que Windows puede exportar es asombroso. Si intentas monitorizar todo, acabarás con un muro de ruido. Para la mayoría de los entornos, debes centrarte en las siguientes áreas principales.
Rendimiento de la CPU y cuellos de botella
El uso de la CPU es la métrica más visible, pero a menudo es un indicador rezagado. Necesitas mirar más allá de un simple porcentaje.
| Métrica | Descripción | Umbral crítico |
|---|---|---|
| % Tiempo de procesador | Utilización básica. | > 80% de forma sostenida |
| Longitud de cola del procesador | Hilos esperando CPU. | > 2x número de núcleos |
| Cambios de contexto/seg | Sobrecarga de CPU gestionando hilos. | Picos altos/inusuales |
Memoria y presión de recursos
Windows es agresivo al usar RAM para caché. Ver un uso de memoria elevado no es siempre una mala señal, pero ver presión de memoria sí lo es.
| Métrica | Descripción | Riesgo |
|---|---|---|
| MBytes disponibles | Memoria física restante para SO/Apps. | < 5-10% de la RAM total |
| Páginas/seg | Fallos de página forzados (intercambio en disco). | Tasas altas deterioran el rendimiento |
| Bytes confirmados | Memoria virtual total comprometida. | Aproximándose a RAM + Archivo de página |
E/S de disco y latencia
El rendimiento del disco es la causa más común de lentitud «silenciosa». Un servidor puede tener un 0% de carga de CPU pero sentirse completamente irresponsivo porque el subsistema de disco está saturado.
| Métrica | Descripción | Objetivo |
|---|---|---|
| Seg/Lectura y Escritura de disco prom. | Mide la latencia en segundos. | < 10ms (Excelente), > 50ms (Cuello de botella) |
| % Tiempo de disco | Porcentaje de tiempo que el disco está ocupado. | El uso sostenido alto es arriesgado |
| Longitud de cola del disco | Solicitudes de E/S esperando al disco. | Correlacionar con alta latencia |
Rendimiento de red y salud
| Métrica | Descripción | Objetivo |
|---|---|---|
| Bytes totales/seg | Uso básico del ancho de banda. | Identificar picos/transferencias |
| Longitud de cola de salida | Paquetes esperando ser enviados. | Debe ser 0 |
| Errores de paquetes recibidos | Paquetes corruptos o fallidos. | Debe ser 0 |
Monitorización de servicios y procesos de Windows
Más allá de las métricas básicas de hardware, debes asegurarte de que tus procesos en segundo plano críticos estén realmente en ejecución. Windows utiliza «Servicios» para gestionar todo, desde tu servidor web (IIS) hasta tu base de datos (SQL Server).
# Comprobar el estado de un servicio específico (ej. Servicio de publicación World Wide Web)
Get-Service -Name W3SVC
# Listar todos los servicios configurados para iniciarse automáticamente pero actualmente detenidos
Get-Service | Where-Object { $_.StartType -eq 'Automatic' -and $_.Status -eq 'Stopped' }- Estado del servicio: Debes monitorizar el estado de cualquier servicio necesario para que tu aplicación funcione. Un servicio configurado como «Automático» pero actualmente «Detenido» es una señal clara de un problema, probablemente un fallo o una dependencia fallida.
- Conjunto de trabajo del proceso: Mide la cantidad de memoria física utilizada actualmente por un proceso específico. Si el conjunto de trabajo de una aplicación sigue creciendo sin nunca disminuir, tienes una fuga de memoria.
- Recuento de manejadores por proceso: Un «manejador» es una referencia a un recurso del sistema (como un archivo o una clave de registro). Si el recuento de manejadores de un proceso aumenta continuamente, está fallando al liberar recursos, lo que eventualmente conducirá a inestabilidad en todo el sistema.
- Retraso de entrada del usuario: En entornos de Escritorio Remoto (RDS), monitorizar el retraso entre la entrada de un usuario y la respuesta de la aplicación es fundamental para comprender la experiencia real del usuario, que las métricas de hardware pueden pasar por alto.
Registros de eventos de Windows
Las métricas te dan el «qué», pero los Registros de Eventos te dan el «quién» y el «cómo». Debes centrarte en estos cuatro registros principales:
- Registro del sistema: Fundamental para problemas de hardware, fallos de controladores y errores a nivel de SO.
- Registro de aplicaciones: Donde tu software (y aplicaciones de terceros) registra sus errores y advertencias.
- Registro de seguridad: Esencial para auditorías. Debes vigilar los inicios de sesión fallidos, los bloqueos de cuentas y los cambios en los grupos administrativos.
- Registro de instalación: Útil durante actualizaciones e instalaciones de nuevo software.
# Obtener los 10 eventos de error más recientes del registro del Sistema
Get-WinEvent -LogName System -MaxEvents 10 | Where-Object { $_.LevelDisplayName -eq "Error" }
# Listar todos los eventos 'Críticos' de las últimas 24 horas
Get-WinEvent -FilterHashtable @{LogName='System'; Level=1; StartTime=(Get-Date).AddDays(-1)}En 2026, no deberías estar desplazándote manualmente por estos registros en el Visor de eventos. Necesitas una forma de centralizar y alertar sobre eventos específicos de nivel «Error» o «Crítico».
Enfoques y herramientas habituales
La elección de una herramienta de monitorización para Windows depende del tamaño de tu entorno y del nivel de complejidad que estés dispuesto a gestionar. Estos son los enfoques más comunes utilizados por los equipos hoy en día.
Herramientas nativas de Microsoft (Sysinternals y PerfMon)
Microsoft proporciona herramientas potentes de serie. El Monitor de rendimiento (PerfMon) es el estándar para el análisis de métricas en tiempo real e histórico en una sola máquina. Para una resolución de problemas profunda, la suite Sysinternals (incluido Process Monitor y Process Explorer) es indispensable.
- Para quién es: Resolución de problemas ad-hoc y análisis profundo de problemas de rendimiento específicos.
- Ventajas: Gratuito, integrado (o fácilmente descargable) y extremadamente detallado.
- Desventajas: Sin alertas centralizadas ni almacenamiento histórico en múltiples servidores. Es un enfoque manual, de un servidor a la vez.
Stacks de código abierto (Prometheus y Grafana)
El enfoque de código abierto más popular en 2026 es usar el windows_exporter para recopilar métricas y enviarlas a un servidor Prometheus, con Grafana para la visualización.
- Para quién es: Equipos cómodos gestionando su propia infraestructura de monitorización basada en Linux para monitorizar su flota de Windows.
- Ventajas: Altamente personalizable, enorme ecosistema y sin costos de licencia para el software.
- Desventajas: Carga operativa significativa. Tienes que gestionar los exportadores, el servidor Prometheus y los paneles de Grafana. Configurar alertas específicas de Windows requiere un conocimiento profundo de las métricas del exportador.
Simple Observability
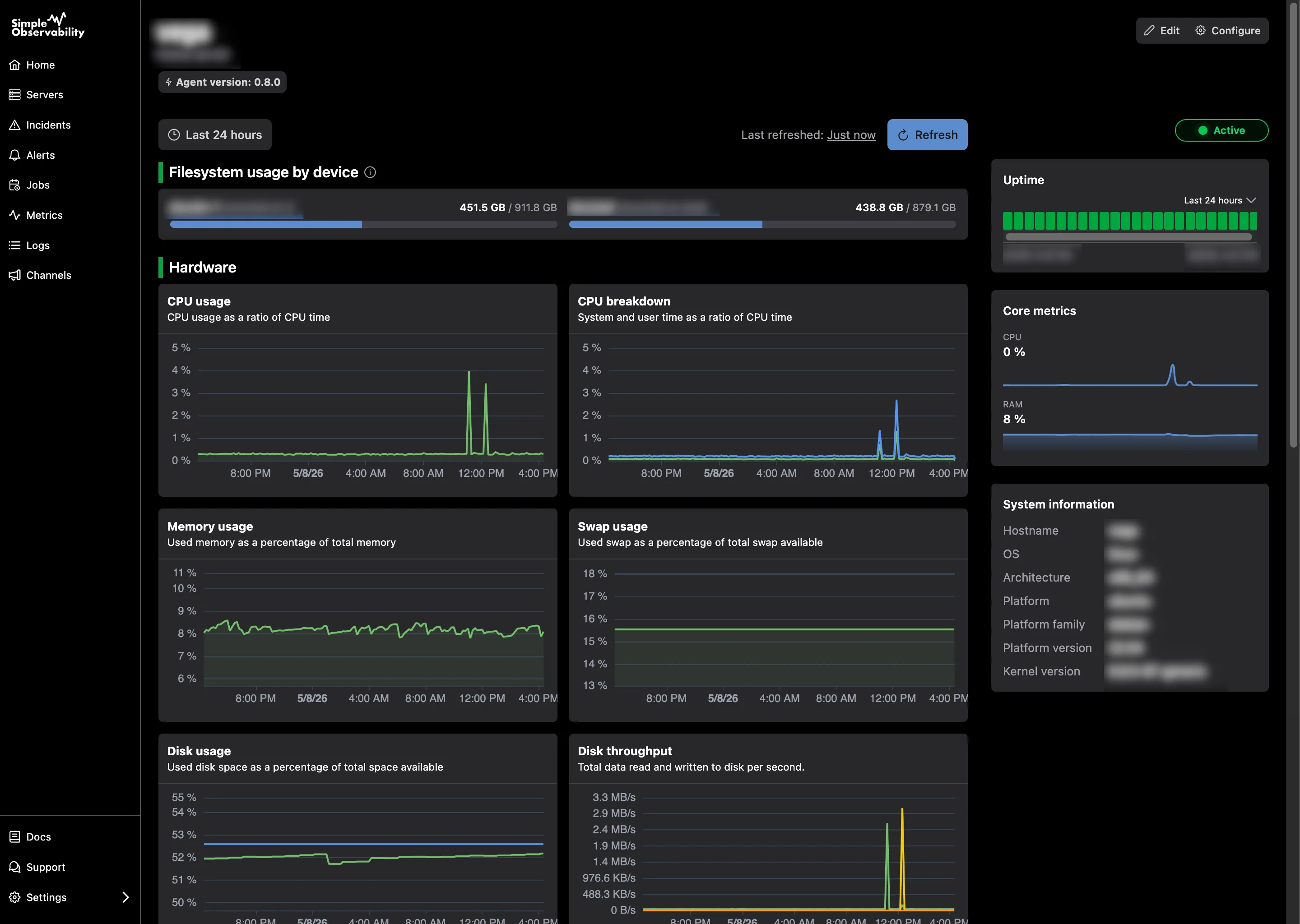
Simple Observability ofrece un enfoque ligero y unificado para monitorizar métricas, registros y alertas en servidores Windows sin la complejidad de los stacks tradicionales. Está diseñado para ser una solución «configurar y olvidar» para equipos que buscan visibilidad de grado de producción en múltiples servidores con una configuración de un solo comando.
- Para quién es: Administradores de sistemas y desarrolladores que quieren visibilidad de grado de producción en múltiples servidores con una configuración de un solo comando.
- Ventajas: Combina métricas y registros de eventos en una interfaz unificada, configuración automática de alertas críticas de Windows y huella de recursos muy baja.
- Desventajas: No está pensado para empresas con miles de servidores y requisitos de nicho ultra especializados.
Plataformas empresariales (Zabbix, SolarWinds, Dynatrace)
Estos son los «grandes actores» del mundo de la monitorización. Ofrecen de todo, desde gestión de activos hasta detección de anomalías impulsada por IA. Sin embargo, muchos equipos buscan alternativas a Zabbix debido a la enorme complejidad y el costo de estas plataformas.
- Para quién es: Grandes empresas con entornos masivos y heterogéneos.
- Ventajas: Características completas y soporte profesional.
- Desventajas: Licencias costosas, curva de aprendizaje pronunciada y a menudo requiere un equipo dedicado solo para gestionar la herramienta de monitorización.
Comparación de herramientas de monitorización de Windows
| Herramienta | Tipo | Complejidad | Mejor para… |
|---|---|---|---|
| PerfMon | Herramienta nativa | Baja | Depuración local rápida |
| Prometheus | Código abierto | Alta | Flotas personalizadas/DIY |
| Simple Observability | SaaS/Unificado | Baja | Equipos pequeños-medianos |
| Zabbix | Empresarial | Alta | Entornos a gran escala |
| Datadog | SaaS/APM | Media | Observabilidad full-stack |
Mejores prácticas para la monitorización de Windows
Configurar una herramienta es solo el primer paso. Para asegurarte de que tu monitorización sea realmente útil, debes seguir estas prácticas recomendadas del sector.
Uno de los mayores errores que cometen los equipos es configurar demasiadas alertas. Si recibes un correo electrónico cada vez que la CPU sube al 90% durante unos segundos, pronto empezarás a ignorar tu bandeja de entrada. Esto es la «fatiga de alertas».
En su lugar, céntrate en problemas sostenidos. Establece tus alertas para que se activen solo cuando una métrica permanezca por encima de un umbral durante una duración específica (por ejemplo, 5-10 minutos). Para Windows específicamente, asegúrate de alertar sobre eventos «Críticos» y «Error» en los registros del Sistema y de Aplicaciones, pero filtra el ruido de «Información».
Establecer una línea base de rendimiento
No puedes saber si tu servidor tiene un rendimiento deficiente si no sabes cómo es lo «normal». Después de configurar tu monitorización, dedica una semana a observar las métricas. ¿Cuál es la carga típica de CPU durante las horas de trabajo? ¿Cuánta RAM suele estar libre? Utiliza estos datos para establecer umbrales de alerta realistas en lugar de depender de los valores predeterminados genéricos.
Usa agentes ligeros
Los servidores Windows a menudo tienen recursos limitados. Evita las herramientas de monitorización que utilicen agentes pesados basados en Java o que dependan en gran medida de WMI. Busca agentes escritos en lenguajes de alto rendimiento como Go o Rust que tengan un impacto mínimo en la CPU y la memoria del sistema anfitrión. Creemos que ser ligero es una métrica, no solo un adjetivo, y priorizamos la eficiencia en cada componente.
Combinar métricas y registros
Nunca monitorices las métricas de forma aislada. Un pico en el uso de CPU tiene muy poco significado si no puedes correlacionarlo con un error en el Registro de Eventos. Un enfoque unificado, donde puedes ver tus gráficas y tus registros en la misma línea de tiempo, reducirá significativamente tu «Tiempo Medio de Resolución» (MTTR).
Monitorizar desde fuera hacia adentro
Las métricas internas te indican si el servidor está sano, pero no te indican si tus usuarios pueden realmente acceder a tu aplicación. Combina siempre tu monitorización interna de Windows con comprobaciones de disponibilidad externas. Esto garantiza que, aunque el servidor esté «en verde», recibirás una alerta si un cambio de firewall o un problema de DNS rompe la conectividad.
Conclusión
La monitorización de Windows en 2026 no tiene que ser una elección entre «complejo» e «incompleto». Al centrarte en las señales fundamentales, específicamente las colas de CPU, la presión de memoria, la latencia del disco y los registros de eventos críticos, puedes construir una estrategia de monitorización sólida que escale con tus necesidades.
Ya sea que elijas construir un stack personalizado con Prometheus, usar las herramientas nativas de Microsoft para la depuración local, u optar por una plataforma unificada como Simple Observability, la clave es pasar de la resolución de problemas reactiva a la gestión proactiva.
Para los equipos que buscan una solución de monitorización de Windows lista para usar, Simple Observability ofrece una configuración de un solo comando y métricas + registros unificados. Te permite dedicar menos tiempo a gestionar tu monitorización y más tiempo a gestionar tu infraestructura.