






Windows Server reste un pilier central de l’infrastructure informatique pour des milliers d’entreprises. Que vous exploitiez une application héritée, un environnement .NET moderne ou une base de données critique, garantir la bonne santé de vos serveurs Windows n’est pas optionnel. C’est la différence entre une nuit tranquille et une session de dépannage d’urgence à 2 h du matin.
En 2026, le paysage de la supervision Windows a évolué. Nous sommes allés bien au-delà des simples vérifications de disponibilité. Les équipes modernes ont besoin d’une visibilité approfondie sur les performances du système, les signaux de sécurité et les journaux d’application. Pourtant, la supervision Windows ressemble souvent à un choix entre deux extrêmes. D’un côté, les outils natifs Microsoft, puissants mais fragmentés. De l’autre, les plateformes d’observabilité d’entreprise, prohibitivement complexes et coûteuses.
Ce guide vise à combler ce fossé. Nous explorerons les principes fondamentaux de la supervision Windows, les métriques spécifiques à suivre et les outils qui vous permettent de le faire efficacement sans la lourdeur des solutions d’entreprise.
Qu’est-ce que la supervision Windows ?
La supervision Windows est le processus continu de collecte et d’analyse des données de votre système d’exploitation Windows et des applications qui s’y exécutent. Elle consiste à observer les ressources physiques et virtuelles du serveur pour s’assurer qu’elles fonctionnent dans les paramètres attendus.
Une erreur courante est de considérer la supervision comme un simple tableau de bord. En réalité, une supervision Windows efficace se compose de trois couches.
Métriques d’infrastructure
Ce sont les valeurs numériques représentant les « signes vitaux » de votre matériel ou de votre VM. Pensez à l’utilisation du processeur, à la pression mémoire et à la latence disque. Elles sont généralement collectées via les Compteurs de performances (PerfMon).
Journaux d’événements
Windows enregistre presque tout ce qui se passe dans le système au sein des Journaux d’événements. Cela inclut les événements de démarrage/arrêt des services, les plantages d’applications, les connexions de sécurité et les erreurs système. Si les métriques indiquent quand un problème est survenu, les journaux indiquent pourquoi il s’est produit.
Santé applicative
Cette couche se concentre sur le logiciel qui importe réellement à vos utilisateurs. Est-ce qu’IIS répond aux requêtes ? Le taux de succès du cache buffer de SQL Server est-il sain ? Superviser la couche applicative garantit que même si le serveur est « disponible », le service fonctionne réellement.
Pourquoi Windows diffère de la supervision Linux
Si vous venez d’un environnement Linux, la supervision Windows peut sembler déroutante. Sous Linux, « tout est un fichier », et vous collectez souvent des métriques en lisant des fichiers texte dans /proc.
Windows utilise une approche plus structurée. Presque toutes les données de performance sont exposées via le système de Compteurs de performances. Accéder à ces données nécessitait traditionnellement des API spécialisées ou WMI (Windows Management Instrumentation). Bien que WMI soit puissant, il est notoirement gourmand en ressources. Les outils de supervision modernes en 2026 privilégient des méthodes plus efficaces comme l’API des Compteurs de performances ou des exportateurs spécialisés.
Compteurs de performances vs. WMI
| Fonctionnalité | WMI | Compteurs de performances |
|---|---|---|
| Ce que c’est | Infrastructure de gestion des données et opérations de l’OS. | Mécanisme de collecte de données haute fréquence. |
| Visibilité | Presque tout (numéros de série, température CPU). | Valeurs numériques mises à jour en mémoire en temps réel. |
| Overhead | Overhead CPU élevé, pouvant causer des problèmes de performance. | Bien plus léger et efficace à interroger. |
La plupart des agents de supervision modernes préfèrent l’API des Compteurs de performances pour les métriques comme le CPU et le disque, réservant WMI aux informations statiques comme la version de l’OS ou la RAM totale installée.
# Lister les compteurs de performances du processeur disponibles
Get-Counter -ListSet Processor | Select-Object -ExpandProperty Counter
# Interroger l'utilisation CPU en temps réel toutes les secondes
Get-Counter -Counter "\Processor(_Total)\% Processor Time" -SampleInterval 1 -MaxSamples 5Que superviser sous Windows ?
Performances du processeur et goulots d’étranglement
| Métrique | Description | Seuil critique |
|---|---|---|
| % Temps processeur | Utilisation de base. | > 80 % de façon soutenue |
| Longueur de file du processeur | Threads en attente de CPU. | > 2x le nombre de cœurs |
| Changements de contexte/sec | Overhead CPU de gestion des threads. | Pics élevés/inhabituels |
Mémoire et pression des ressources
| Métrique | Description | Risque |
|---|---|---|
| Mo disponibles | Mémoire physique restante pour l’OS/les Apps. | < 5-10 % de la RAM totale |
| Pages/sec | Défauts de page forcés (swap disque). | Des taux élevés détruisent les performances |
| Octets validés | Mémoire virtuelle totale engagée. | Approche RAM + fichier d’échange |
E/S disque et latence
Les performances disque sont la cause la plus fréquente de lenteur « silencieuse ». Un serveur peut afficher 0 % de charge CPU mais sembler totalement figé parce que le sous-système disque est saturé.
| Métrique | Description | Objectif |
|---|---|---|
| Sec/Lecture et Écriture moy. | Latence en secondes. | < 10 ms (Excellent), > 50 ms (Goulot) |
| % Temps disque | Pourcentage du temps que le disque est occupé. | Utilisation soutenue élevée est risquée |
| Longueur de file du disque | Requêtes E/S en attente. | Corréler avec une latence élevée |
Débit réseau et santé
| Métrique | Description | Objectif |
|---|---|---|
| Total octets/sec | Utilisation de base de la bande passante. | Identifier les pics/transferts |
| Longueur de file de sortie | Paquets en attente d’envoi. | Doit être 0 |
| Erreurs de paquets reçus | Paquets corrompus ou en échec. | Doit être 0 |
Supervision des services et processus Windows
Au-delà des métriques matérielles, vous devez vous assurer que vos processus d’arrière-plan critiques sont bien actifs. Windows utilise les « Services » pour gérer tout, de votre serveur web (IIS) à votre base de données (SQL Server).
# Vérifier le statut d'un service spécifique (ex : IIS)
Get-Service -Name W3SVC
# Lister les services configurés pour démarrer automatiquement mais actuellement arrêtés
Get-Service | Where-Object { $_.StartType -eq 'Automatic' -and $_.Status -eq 'Stopped' }- Santé des services : Un service configuré en « Automatique » mais actuellement « Arrêté » est un signal clair de problème, probablement un crash ou une dépendance défaillante.
- Working set du processus : Mesure la mémoire physique utilisée par un processus. Si elle croît sans jamais diminuer, vous avez une fuite mémoire.
- Nombre de handles par processus : Si ce nombre augmente continuellement, le processus ne libère pas ses ressources, ce qui mènera à une instabilité du système.
- Délai de saisie utilisateur : Dans les environnements RDS, crucial pour comprendre l’expérience réelle de l’utilisateur.
Journaux d’événements Windows
Les métriques disent « quoi », les Journaux d’événements disent « qui » et « comment ». Concentrez-vous sur ces quatre journaux principaux :
- Journal système : Critique pour les problèmes matériels, les échecs de pilotes et les erreurs OS.
- Journal des applications : Là où vos logiciels et applications tierces enregistrent erreurs et avertissements.
- Journal de sécurité : Essentiel pour l’audit. Surveillez les échecs de connexion, les verrouillages de comptes et les modifications des groupes administrateurs.
- Journal d’installation : Utile lors des mises à jour et nouvelles installations.
# Obtenir les 10 événements d'erreur les plus récents du journal Système
Get-WinEvent -LogName System -MaxEvents 10 | Where-Object { $_.LevelDisplayName -eq "Error" }
# Lister tous les événements 'Critiques' des dernières 24 heures
Get-WinEvent -FilterHashtable @{LogName='System'; Level=1; StartTime=(Get-Date).AddDays(-1)}En 2026, vous ne devriez pas faire défiler manuellement ces journaux dans l’Observateur d’événements. Vous avez besoin d’un moyen de centraliser et d’alerter sur des événements de niveau « Erreur » ou « Critique ».
Approches et outils courants
Outils natifs Microsoft (Sysinternals et PerfMon)
- Pour qui : Dépannage ad-hoc et analyse approfondie de problèmes de performance spécifiques.
- Avantages : Gratuit, intégré (ou facilement téléchargeable) et extrêmement détaillé.
- Inconvénients : Pas d’alertes centralisées ni de stockage historique sur plusieurs serveurs. Approche manuelle, serveur par serveur.
Stacks open source (Prometheus et Grafana)
L’approche open source la plus courante en 2026 consiste à utiliser le windows_exporter pour collecter les métriques et les envoyer à un serveur Prometheus, avec Grafana pour la visualisation.
- Pour qui : Équipes à l’aise pour gérer leur propre infrastructure de supervision basée sur Linux.
- Avantages : Hautement personnalisable, vaste écosystème, pas de coûts de licence logicielle.
- Inconvénients : Charge opérationnelle significative. Vous gérez les exportateurs, le serveur Prometheus et les tableaux de bord Grafana.
Simple Observability
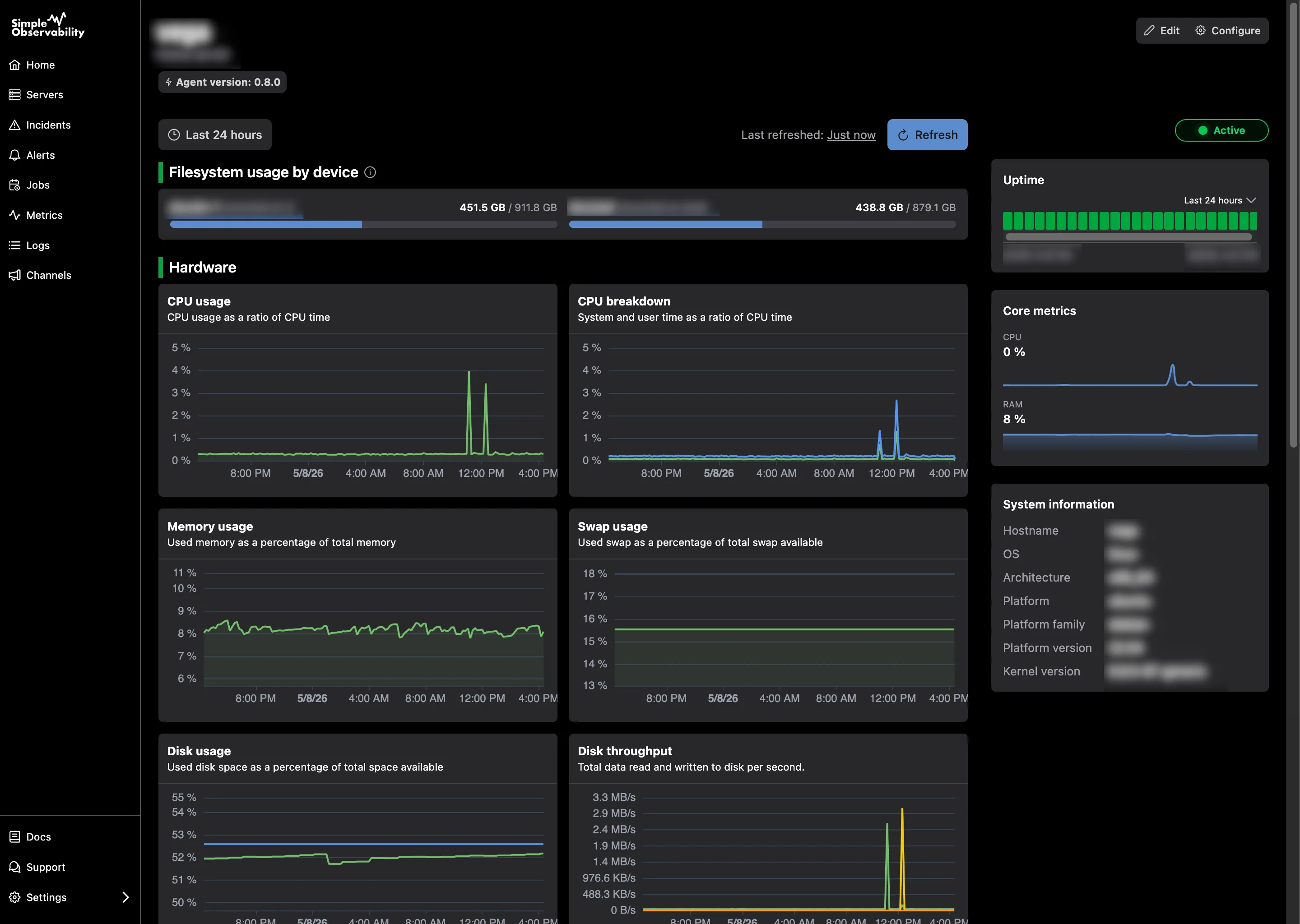
Simple Observability propose une approche légère et unifiée pour superviser métriques, journaux et alertes sur des serveurs Windows sans la complexité des stacks traditionnels. Conçue pour être une solution « configurer et oublier » pour les équipes souhaitant une visibilité de niveau production sur plusieurs serveurs avec une installation en une seule commande.
- Pour qui : Sysadmins et développeurs souhaitant une visibilité de niveau production sur plusieurs serveurs, avec une installation en une commande.
- Avantages : Combine métriques et journaux d’événements dans une interface unifiée, alertes Windows critiques automatiques et empreinte ressources très faible.
- Inconvénients : Non destiné aux grandes entreprises avec des milliers de serveurs et des exigences ultra-spécialisées.
Plateformes d’entreprise (Zabbix, SolarWinds, Dynatrace)
- Pour qui : Grandes entreprises avec des environnements massifs et hétérogènes.
- Avantages : Fonctionnalités complètes et support professionnel.
- Inconvénients : Licences coûteuses, courbe d’apprentissage abrupte et souvent une équipe dédiée uniquement à la gestion de l’outil.
Comparaison des outils de supervision Windows
| Outil | Type | Complexité | Idéal pour… |
|---|---|---|---|
| PerfMon | Outil natif | Faible | Débogage local rapide |
| Prometheus | Open Source | Élevée | Flottes personnalisées/DIY |
| Simple Observability | SaaS/Unifié | Faible | Petites-moyennes équipes |
| Zabbix | Entreprise | Élevée | Environnements à grande échelle |
| Datadog | SaaS/APM | Moyenne | Observabilité full-stack |
Bonnes pratiques pour la supervision Windows
L’une des plus grandes erreurs des équipes est de configurer trop d’alertes. Si vous recevez un e-mail à chaque fois que le CPU dépasse 90 % pendant quelques secondes, vous finirez par ignorer votre boîte de réception. C’est la « fatigue d’alertes ».
Concentrez-vous plutôt sur les problèmes persistants. Configurez vos alertes pour se déclencher uniquement lorsqu’une métrique reste au-dessus d’un seuil pendant une durée spécifique (ex : 5-10 minutes). Pour Windows, assurez-vous d’alerter sur les événements « Critique » et « Erreur » dans les journaux Système et Application, en filtrant le bruit « Informations ».
Établir une ligne de base de performance
Après avoir configuré votre supervision, passez une semaine à observer les métriques. Quelle est la charge CPU typique pendant les heures de bureau ? Combien de RAM est généralement libre ? Utilisez ces données pour définir des seuils d’alerte réalistes plutôt que de vous fier à des valeurs par défaut génériques.
Utiliser des agents légers
Les serveurs Windows sont souvent limités en ressources. Évitez les outils utilisant des agents Java lourds ou dépendant fortement de WMI. Cherchez des agents écrits dans des langages performants comme Go ou Rust. Nous croyons que la légèreté est une métrique, pas seulement un adjectif.
Combiner métriques et journaux
Ne supervisez jamais les métriques de façon isolée. Un pic d’utilisation CPU a peu de sens si vous ne pouvez pas le corréler avec une erreur dans le Journal d’événements. Une approche unifiée, où vous voyez vos graphiques et vos journaux sur la même timeline, réduira significativement votre « Temps Moyen de Résolution » (MTTR).
Superviser de l’extérieur vers l’intérieur
Les métriques internes indiquent si le serveur est sain, mais pas si vos utilisateurs peuvent accéder à votre application. Combinez toujours votre supervision interne Windows avec des vérifications de disponibilité externes. Ainsi, même si le serveur est « vert », vous serez alerté si un changement de pare-feu ou un problème DNS coupe la connectivité.
Conclusion
La supervision Windows en 2026 n’a pas à être un choix entre « complexe » et « incomplet ». En vous concentrant sur les signaux essentiels — files d’attente CPU, pression mémoire, latence disque et journaux d’événements critiques — vous pouvez bâtir une stratégie de supervision robuste qui s’adapte à vos besoins.
Que vous choisissiez un stack personnalisé avec Prometheus, les outils natifs Microsoft pour le débogage local, ou une plateforme unifiée comme Simple Observability, la clé est de passer d’une résolution de problèmes réactive à une gestion proactive.
Pour les équipes cherchant une solution Windows prête à l’emploi, Simple Observability propose une installation en une commande et des métriques + journaux unifiés — pour passer moins de temps à gérer votre supervision et plus de temps à gérer votre infrastructure.