

Netdata es una plataforma de monitorización de código abierto conocida por su arquitectura distribuida edge-first que permite métricas en tiempo real con granularidad de un segundo. Aunque este enfoque es potente para ciertos casos de uso, tiene sus compromisos: mayor consumo de recursos en cada nodo y complejidad al escalar a cientos de servidores.
Si buscas algo más simple, Simple Observability ofrece una alternativa ligera. Está construida alrededor de un agente de código abierto que usa recursos mínimos y se instala literalmente con un comando. Todo lo demás se configura a través de la interfaz, así que puedes olvidarte de lidiar con archivos YAML.
En este artículo, repasaremos las mejores alternativas a Netdata en 2026. Empezaremos con una visión general de lo que Netdata hace bien (y dónde tiene problemas), luego cubriremos los criterios clave que debes considerar al evaluar herramientas de monitorización. Finalmente, compararemos cada opción para ayudarte a encontrar la más adecuada para tu equipo.
Visión general de Netdata
Conocido por
Netdata es conocido principalmente por sus datos en tiempo real de alta resolución. La plataforma recopila métricas del sistema cada segundo y mantiene aproximadamente 1 segundo de latencia desde la recopilación hasta la visualización. Está diseñado para solucionar problemas inmediatos cuando necesitas ese nivel de granularidad.
Características clave
- Métricas en tiempo real: Granularidad de un segundo para retroalimentación inmediata.
- ML no supervisado: Detección de anomalías integrada que marca valores atípicos sin umbrales manuales.
- Autodescubrimiento: Detecta automáticamente servicios y aplicaciones ejecutándose en el host.
- Arquitectura distribuida: Los datos se almacenan típicamente en el edge (en el propio nodo), lo que reduce costos de almacenamiento central pero aumenta el uso de recursos locales.
¿Por qué buscar una alternativa a Netdata?
Aunque Netdata destaca en la monitorización en tiempo real de nodos individuales, su arquitectura crea algunos desafíos prácticos.
1. Escalabilidad en entornos dinámicos
La naturaleza distribuida de Netdata funciona bien para la eficiencia de almacenamiento, pero gestionar cientos de contenedores efímeros o microservicios se complica rápidamente. Agregar datos de miles de nodos típicamente requiere configuración significativa, o terminas dependiendo de Netdata Cloud, que trae sus propios costos y complejidad.
2. Sobrecarga de recursos
Como Netdata procesa datos de alta resolución y ejecuta detección de anomalías directamente en cada agente, usa más CPU y RAM que reenviadores ligeros como Telegraf o el agente de Simple Observability. En entornos con recursos limitados, este efecto observador puede ser un problema real.
3. Pilares de observabilidad faltantes
Netdata es principalmente una herramienta de métricas. Recientemente añadió manejo de logs (indexando logs en el edge), pero aún carece de soporte nativo para trazado distribuido. Eso está en su hoja de ruta para 2026, pero si necesitas observabilidad completa (métricas, logs y trazas) hoy, tendrás que combinar múltiples herramientas.
¿Cómo elegir una alternativa?
Al evaluar alternativas, considera estos criterios fundamentales:
- Eficiencia del agente: Busca agentes ligeros escritos en lenguajes eficientes (Go, Rust, C++) que no impacten tus cargas de trabajo de producción.
- Observabilidad unificada: ¿La herramienta soporta métricas, logs y alertas en un solo panel?
- Facilidad de uso: ¿Puedes configurarla en minutos (tiempo hasta obtener valor), o requiere semanas de configuración?
- Precio: ¿El modelo de precios es predecible? Evita herramientas con facturación medida compleja si tienes un presupuesto estricto.
Resumen rápido
| Herramienta | Mejor para | Modelo de precio |
|---|---|---|
| Simple Observability | Simplicidad y unificación | Tarifa plana por servidor |
| Prometheus y Grafana | Cloud nativo / K8s | Gratis (autohospedado) |
| Checkmk | IT complejo / híbrido | Por servicio (~$6/host/mes) |
| Datadog | Empresas / nube | Por host + uso de datos |
| New Relic | Rendimiento de apps (APM) | Basado en uso (GBs/usuarios) |
| Icinga | Configuración flexible | Gratis (código abierto) |
| Zabbix | Redes / on-premise | Gratis (código abierto) |
| Nagios | Estabilidad legacy | Basado en licencia |
8 Mejores alternativas a Netdata
1. Simple Observability
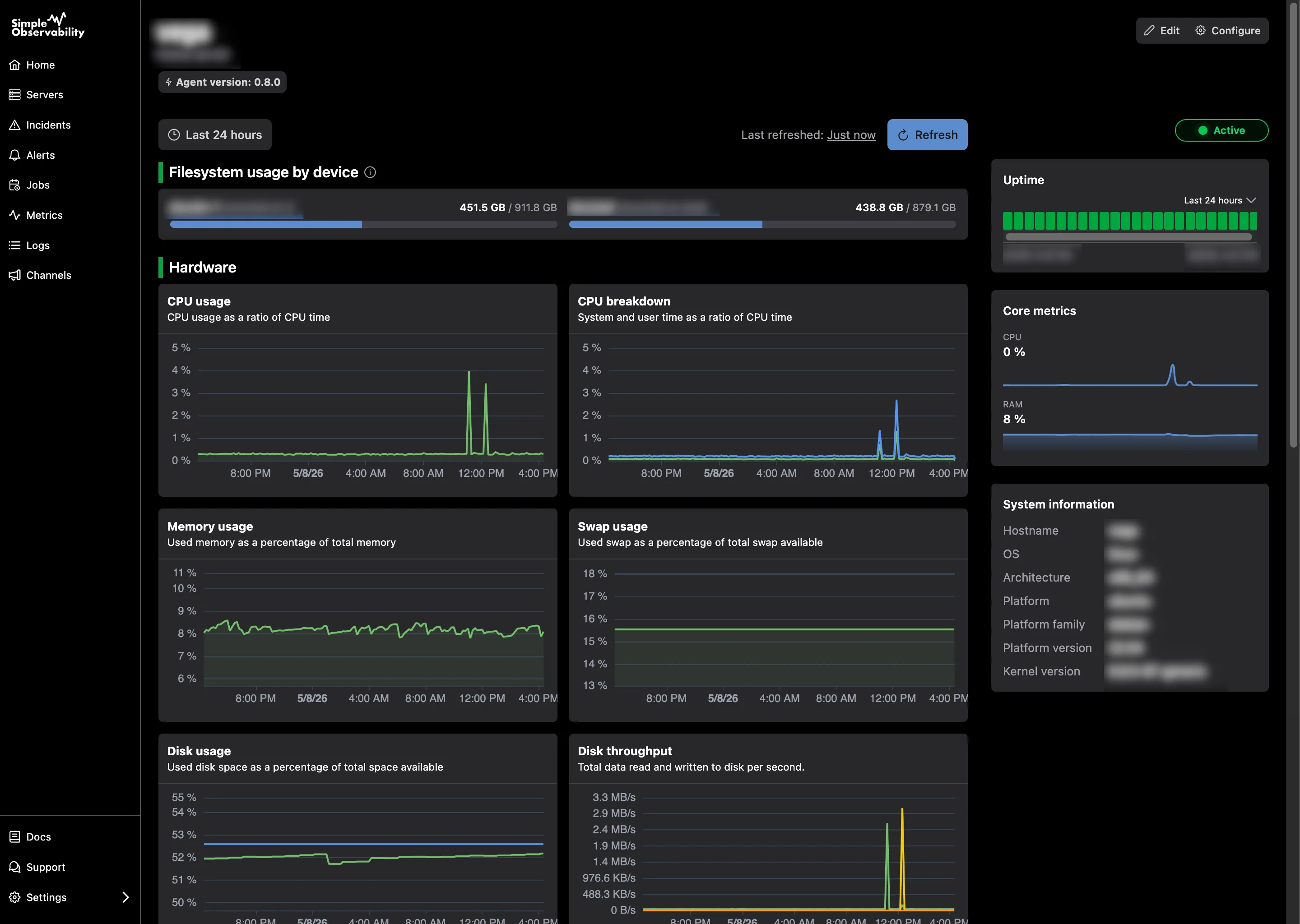
Simple Observability es una plataforma de monitorización de servidores diseñada para ser la alternativa más directa para equipos que quieren resultados sin complicaciones. Combina métricas y logs en una interfaz unificada, reemplazando tres herramientas separadas (métricas, logs, uptime) con una sola.
Características clave
- Panel unificado: Visualiza picos de CPU/memoria junto a logs de aplicación en la misma vista.
- Alarmas sin configuración: Viene con valores predeterminados sensatos para que estés protegido desde el día uno.
- Agente ligero: Agente de código abierto altamente optimizado que respeta los recursos de tu servidor.
- Conveniencia SaaS: No necesitas alojar tu propia base de datos de métricas o stack de retención.
Simple Observability vs Netdata A diferencia de Netdata, que puede ser abrumador con miles de métricas desde el inicio, Simple Observability se enfoca en señal sobre ruido. Proporciona las métricas críticas que realmente necesitas para ejecutar sistemas de producción, almacenadas centralmente para que no pierdas datos si un nodo muere (un riesgo con el almacenamiento local predeterminado de Netdata).
Ventajas
- Extremadamente fácil de usar: Instalación con un comando, sin configuración necesaria.
- Precio predecible: Tarifa plana por servidor. Sin sorpresas de “por millón de métricas personalizadas” o “por GB de log”.
- Datos históricos completos: Retención a largo plazo incluida por defecto.
Desventajas
- Menos granular: Netdata ofrece resolución de 1 segundo; Simple Observability usa intervalos estándar de 10-60s para mantener costos y ancho de banda razonables.
Mejor para: Startups, agencias y equipos DevOps que quieren una solución de monitorización “configurar y olvidar” que simplemente funcione.
Precio
- Lite: Gratis para 1 servidor.
- Standard: $9/mes para 3 servidores.
- Advanced: $21/mes para 5 servidores.
2. Prometheus y Grafana
Prometheus junto con Grafana es el estándar de la industria para monitorización cloud-native. Es una combinación potente de código abierto donde Prometheus recopila las métricas y Grafana las visualiza.
Características clave
- Modelo de datos multidimensional: Consultas potentes usando PromQL.
- Ecosistema enorme: Exportadores disponibles para casi cualquier software existente (Redis, Postgres, Nginx, etc.).
- Alertmanager: Maneja alertas con enrutamiento y agrupación sofisticados.
Ventajas
- Estándar de la industria: La opción de facto para monitorización de Kubernetes.
- Código abierto: Completamente gratis si se autoaloja.
- Flexibilidad: Puedes construir cualquier panel imaginable en Grafana.
Desventajas
- Complejidad: Requiere configurar y mantener dos piezas de software separadas (Prometheus + Grafana).
- Almacenamiento: Eres responsable de gestionar almacenamiento a largo plazo y copias de seguridad (a menudo requiere añadir Thanos o Cortex para escalabilidad).
- Curva de aprendizaje pronunciada: PromQL es potente pero lleva tiempo dominarlo comparado con interfaces de apuntar y hacer clic.
Mejor para: Entornos Kubernetes, equipos de ingeniería de plataforma y organizaciones con recursos SRE dedicados.
Precio Gratis (código abierto). Las versiones gestionadas (Amazon Managed Prometheus, Grafana Cloud) tienen precios basados en uso.
3. Checkmk
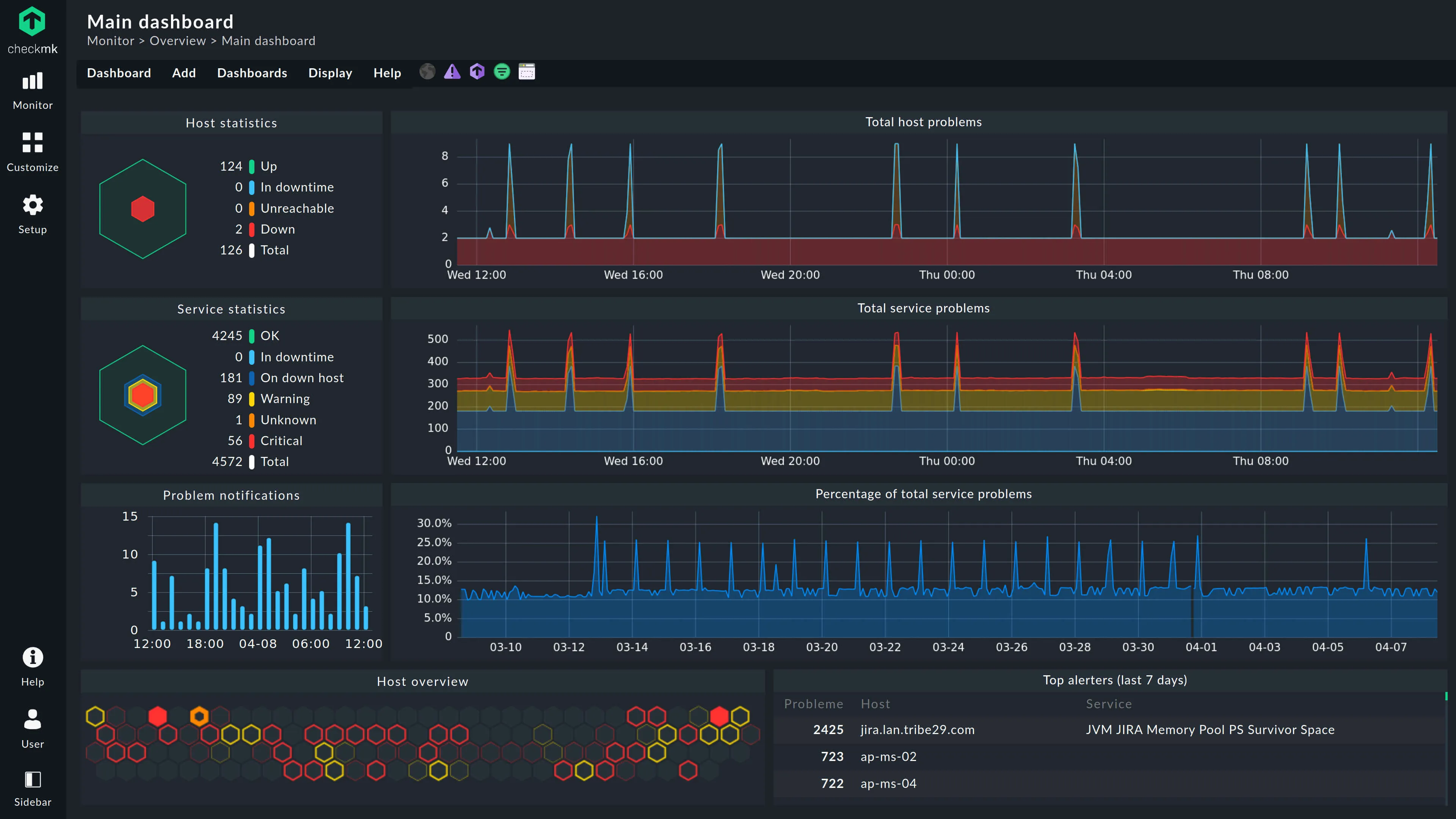
Checkmk es una herramienta de monitorización integral que destaca en entornos IT complejos e híbridos. Cierra la brecha entre las comprobaciones estilo Nagios de la vieja escuela y la recopilación moderna de métricas.
Características clave
- Monitorización híbrida: Igualmente bueno monitorizando bare metal, switches y contenedores Docker.
- Descubrimiento automático de servicios: Escanea hosts para encontrar automáticamente servicios en ejecución y configurar comprobaciones.
- Más de 2,000 plugins: Biblioteca masiva de integraciones.
Ventajas
- Todo en uno: Maneja bien tanto monitorización basada en estados (Arriba/Abajo) como rendimiento de métricas.
- Escalable: Puede manejar miles de servicios en un solo servidor gracias a su núcleo eficiente.
Desventajas
- UI/UX: La interfaz, aunque funcional, puede sentirse desordenada y anticuada comparada con herramientas SaaS modernas.
- Configuración: Extremadamente potente pero tiene una curva de aprendizaje pronunciada para características avanzadas.
Mejor para: Administradores de sistemas y departamentos IT que gestionan una mezcla de hardware legacy, servidores on-premise e instancias en la nube.
Precio La edición de código abierto es gratuita. Enterprise comienza en ~$2,100/año para 3,000 servicios (aprox. 100 hosts). Las ediciones SaaS comienzan en ~$6 por host/mes (facturado por servicio).
4. Datadog
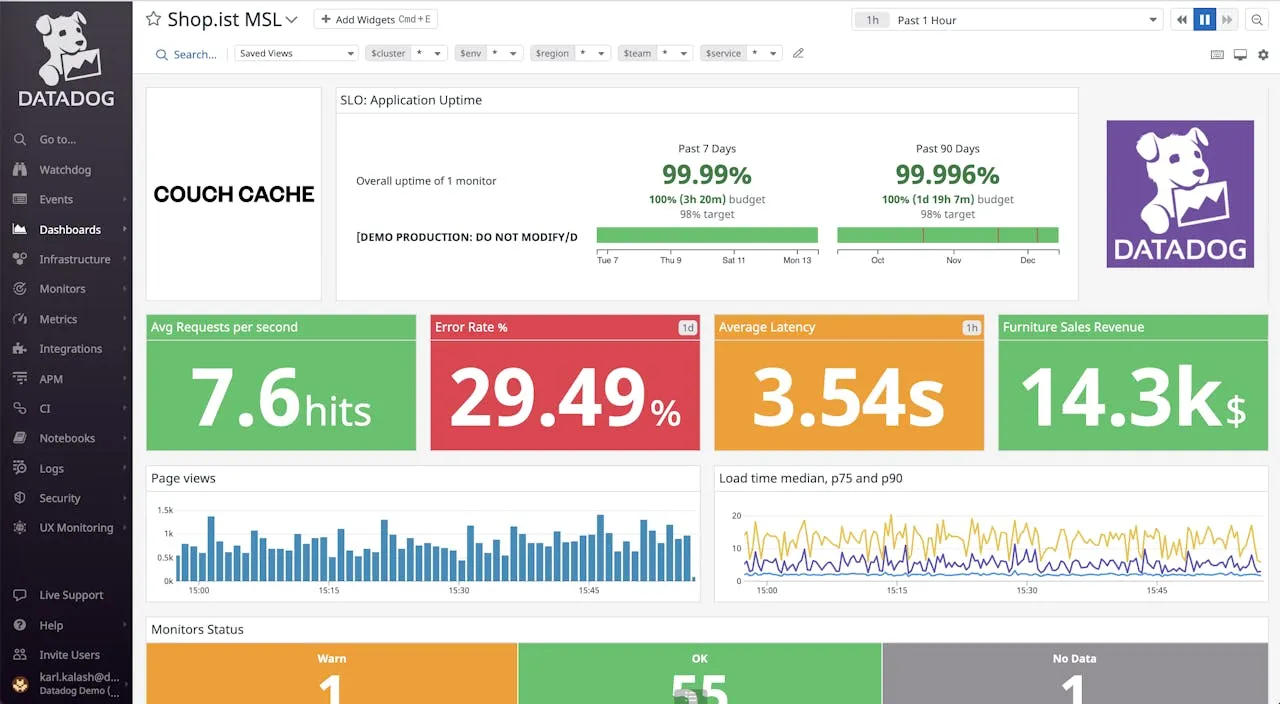
Datadog es el gigante del espacio de observabilidad. Ofrece una plataforma masiva y unificada que cubre todos los ángulos posibles de monitorización: infraestructura, APM, logs, seguridad, red y RUM.
Características clave
- Observabilidad full-stack: Correlación de datos verdaderamente unificada entre trazas, logs y métricas.
- Watchdog AI: Detección automatizada de anomalías que a menudo detecta problemas antes que tú.
- Más de 400 integraciones: Integraciones de apuntar y hacer clic para AWS, Azure, Google Cloud y herramientas SaaS.
Ventajas
- Interfaz pulida: Intuitiva, rápida y genuinamente agradable de usar.
- Visibilidad profunda: El nivel de información para APM y trazado es inigualable.
Desventajas
- Costo: Infamemente caro. El precio “por host” es solo el boleto de entrada; métricas personalizadas, ingesta de logs y retención se suman rápidamente.
- Dependencia del proveedor: El agente propietario y el formato de datos hacen difícil salir una vez que estás profundamente integrado.
Mejor para: Grandes empresas y compañías tecnológicas de alto crecimiento donde la velocidad de ingeniería es más valiosa que optimizar la factura de monitorización.
Precio Infraestructura comienza en $15/host/mes. APM, logs y métricas personalizadas se facturan por separado y adicionalmente.
5. New Relic
New Relic es un veterano en el espacio APM que ha evolucionado a una plataforma de observabilidad completa. Es particularmente fuerte para desarrolladores que necesitan visibilidad profunda a nivel de código para depurar problemas de rendimiento de aplicaciones.
Características clave
- APM profundo: Trazado a nivel de código para identificar consultas de base de datos lentas o funciones ineficientes.
- Navegador y móvil: Soporte nativo para rastrear experiencia de usuario final (RUM) en aplicaciones web y móviles.
- Inteligencia aplicada: Información impulsada por IA para detectar anomalías y correlacionar eventos.
Ventajas
- Plataforma de datos unificada: Toda la telemetría (métricas, logs, trazas) se almacena en un lugar.
- Nivel gratuito: Nivel gratuito generoso (100 GB/mes) para equipos pequeños.
Desventajas
- Complejidad: La plataforma es vasta, y navegar la interfaz puede ser abrumador para necesidades simples.
- Modelo de precios: Aunque el nivel gratuito es bueno, el precio por usuario para acceso completo puede volverse caro para equipos más grandes.
Mejor para: Equipos de desarrollo enfocados en monitorización de rendimiento de aplicaciones (APM) y depuración full-stack.
Precio Basado en uso: gratis para 100 GB/mes. Los planes Pro/Enterprise cobran por usuario + ingesta de datos.
6. Icinga
Nacido como un fork de Nagios, Icinga ha modernizado el enfoque clásico de monitorización. Retiene la compatibilidad con plugins de Nagios pero añade una interfaz web moderna, una API de configuración robusta y características de escalabilidad.
Características clave
- Icinga Director: Una herramienta basada en web para gestionar configuración, haciéndolo más fácil que editar archivos de configuración.
- Monitorización distribuida: Soporte integrado para configuraciones distribuidas y alta disponibilidad.
- Compatibilidad de plugins: Compatible con miles de plugins existentes de Nagios.
Ventajas
- Clásico modernizado: Obtén la confiabilidad de Nagios con una interfaz y API mucho mejores.
- Código abierto: Los componentes principales son gratuitos y de código abierto.
Desventajas
- Esfuerzo de configuración: Aún requiere configuración y ajuste significativos comparado con herramientas SaaS.
- Curva de aprendizaje: Entender el lenguaje de configuración y el modelo de objetos lleva tiempo.
Mejor para: Administradores de sistemas que aman la flexibilidad de Nagios pero quieren una herramienta más moderna, impulsada por API y escalable.
Precio Gratis (código abierto). Soporte comercial disponible.
7. Zabbix
Zabbix es una plataforma de código abierto madura y de nivel empresarial. Es una potencia de monitorización tradicional, favorecida por ingenieros de redes y grandes empresas tradicionales.
Características clave
- Con agente y sin agente: Puede monitorizar vía SNMP, JMX, IPMI y su propio agente.
- Push y pull: Soporta tanto métodos de recopilación de datos por polling como por trapping.
- Permisos granulares: Excelentes controles de permisos de usuario y multi-tenencia.
Ventajas
- Gratis: Verdaderamente 100% código abierto sin características “Enterprise” bloqueadas.
- Probado: Probado en batalla en entornos masivos durante décadas.
Desventajas
- Complejidad: La configuración puede ser muy verbosa (XML/plantillas) y consumir mucho tiempo.
- Modernidad: Carece de las integraciones cloud-native fluidas y la sensación fluida de herramientas de observabilidad modernas.
Mejor para: Centros de operaciones de red (NOCs), MSPs y organizaciones con infraestructura on-premise pesada y presupuesto cero para licencias de software.
Precio Gratis (código abierto). Solo pagas por tu propia infraestructura para alojarlo.
8. Nagios
Nagios es el “abuelo” de la monitorización. Aunque efectivamente se considera tecnología legacy según estándares modernos, todavía está ampliamente desplegado debido a su estabilidad y vasto ecosistema de scripts de comprobación.
Características clave
- Ecosistema de plugins: Si un dispositivo existe, probablemente hay un script Perl o Bash para monitorizarlo en Nagios.
- Enfoque en estado binario: Excelente para alertas definitivas “OK/CRÍTICO”.
Ventajas
- Confiabilidad: Extremadamente estable y simple en su lógica.
- Universal: Casi todos los administradores de sistemas saben cómo leer una alerta de Nagios.
Desventajas
- Anticuado: La configuración es basada en archivos y frágil. La interfaz es de otra era.
- Métricas: Es fundamentalmente una herramienta de comprobación de estado, no una herramienta de métricas/gráficos. Usualmente necesitas emparejarlo con algo más para gráficos.
Mejor para: Entornos legacy donde “si no está roto, no lo arregles” aplica, o para comprobaciones de hardware muy específicas que solo los plugins de Nagios soportan.
Precio Nagios Core es gratis. Nagios XI (comercial) comienza en $1,995 para 50 nodos.
Conclusión
Netdata es una herramienta fantástica para lo que hace: darte una vista increíblemente de alta resolución de un solo servidor, efectivamente gratis. Pero para muchos equipos, la complejidad de escalarlo y la falta de logs integrados e historial de alertas lo convierten en un trampolín en lugar de un destino final.
- Para el mejor equilibrio de simplicidad y potencia: Prueba Simple Observability. Simplifica el caos en un panel limpio y accionable.
- Para Kubernetes/cloud-native: Ve con Prometheus + Grafana.
- Para presupuestos empresariales profundos: Datadog es la opción de lujo.
Elige la herramienta que se ajuste a las habilidades de tu equipo y al presupuesto de tu organización.